It is noted that studying the patterns of development of innovative solutions applicable in lawmaking is of scientific and practical interest to both academics and practicing lawyers — draft legislation developers. The article addresses certain issues of applying machine learning models to predict the validity of decisions made when developing legislative solutions. Attention is drawn to the fact that an algorithmic approach is advisable to apply at the initial stage of developing a proposed legislative act. The article presents a methodology for building a baseline model to predict whether bills will be adopted by the State Duma of the Federal Assembly of the Russian Federation (hereinafter — the State Duma), based solely on structured metadata without using document texts. The analytical part of the article is based on a dataset comprising 34 189 bills (1994–2025) with verified outcomes. A feature space of 20 variables has been developed, including the type and faction of the initiator, committee‑related features, temporal characteristics, as well as two leakage‑safe rolling features: rolling_success_rate (with exponential weighting, half‑life 5 years) and faction_success_rate (cumulative average of the faction), and a drift‑proxy feature days_since_conv_start. A three‑stage procedure for preprocessing target labels is described (State Duma API → logical rules → parsing the Legislative Support System (hereinafter — LSS)), which reduced the proportion of missing values from 15 % to 1.3 %. It is noted that a Random Forest model with time‑based cross‑validation (TimeSeriesSplit, 5 folds) achieved a ROC‑AUC of 0.8989 ± 0.050. In turn, it is observed that an extended model M2a, which includes features of institutional support extracted from the LSS parser, improved the ROC‑AUC to 0.9709 (+0.069). It has been established that the initiator type (importance 0.310) and the rolling success rate (0.176) jointly account for 48.6 % of feature importance, outperforming the substantive characteristics of the bill. Conclusions on the studied issue are presented.
Keywords : machine learning, legislative process, Baseline model, Random Forest, feature engineering, temporal validation, rolling features, SHAP, State Duma, ROC‑AUC.
1 Введение
В современной научной литературе отмечается возрастающий интерес к изучению закономерностей развития инновационных решений, применимых в сфере законотворчества. Данная проблематика представляет научную и практическую ценность как для академического сообщества, исследующих теоретические проблемы права, так и для практикующих юристов — непосредственных разработчиков законопроектов.
Нынешняя интеграция инновационных подходов способна повысить эффективность законодательного процесса, оптимизировать законотворческую деятельность, обеспечивая более точное соответствие нормативных актов актуальным социально‑экономическим реалиям.
В зарубежной научной литературе отмечается, что прогнозирование законодательного процесса помимо традиционных средств и методик может основываться и на моделях машинного обучения [12, 8], анализ которых показывает, что некоторые результаты продемонстрировали наилучший результат полного текста законопроекта над метаданными, [1]. Так, например в результате использования ансамблевых методов классификации была достигнута точность (accuracy) модели, составляющая 80 % на тестовой выборке. В частности, для российского парламента ключевым исследованием в данной области является работа М. В. Хавроненко [11]. В рамках его исследования на корпусе из 27 176 законопроектов, размещенных на официальном сайте Государственной Думы была применена модель rubert‑tiny, что позволило достичь значения метрики F1 = 0,937 при использовании логистической регрессии для классификации текстов законодательных актов.
Настоящая статья с точки зрения научного исследования ставит следующий вопрос: каков предел качества предсказания, достижимый исключительно на структурированных метаданных — без доступа к текстам документов? Ответ важен по двум причинам. Во-первых, метаданные доступны немедленно в момент внесения законопроекта, тогда как тексты документов появляются позже. Во-вторых, качество baseline-модели само по себе является научным результатом, характеризующим процедурную предсказуемость российского законодательного процесса. Дополнительной научной задачей является построение корректной стратегии валидации, исключающей утечку данных — принципиального требования при работе с хронологически упорядоченными данными. Кроме того, акцентируется внимание на целесообразности применения алгоритмизированных подходов на начальной стадии разработки проектируемого законодательного акта. Указанное позволяет повысить качество законодательного текста, минимизировать концептуальные ошибки и оптимизировать временные затраты на последующих этапах законотворческого процесса.
Для понимания масштаба задачи необходимо оценить объём законотворческой деятельности Государственной Думы. Рисунок № 1 отражает динамику разработки законопроектов по созывам IV–VIII с разбивкой на принятые и отклонённые законодательные инициативы. Данные демонстрируют устойчивый рост законотворческой активности и умеренный дисбаланс классов (≈34,2 %), что обусловливает выбор ROC-AUC как основной метрики.
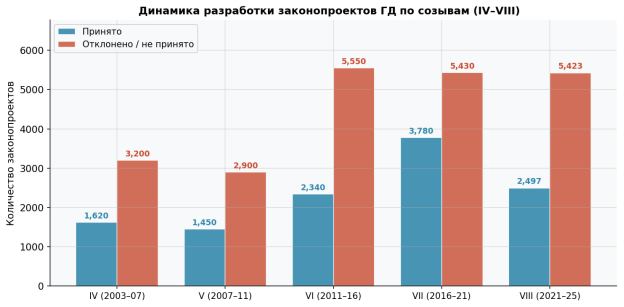
Рис. 1. Динамика разработки законопроектов ГД по созывам (IV–VIII): принятые и отклонённые
Законодательная воронка (Рисунок № 2) показывает, что не значительная часть внесённых законопроектов проходят все три чтения. Факт постановки на второе чтение резко повышает вероятность итогового принятия — этот паттерн используется в моделях M2a/M2b через признак readings_count.
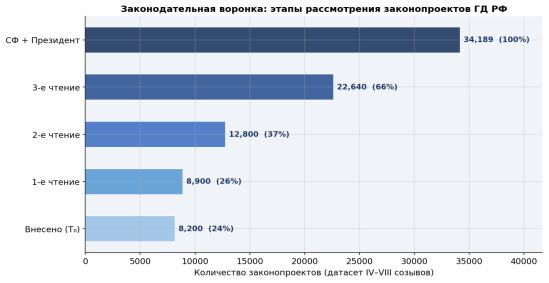
Рис. 2. Законодательная воронка: этапы рассмотрения законопроектов ГД (34 189 записей)
2 Baseline-модель и инженерия признаков
В данном разделе представлена характеристика baseline-модели, ее применение в законотворчестве, возможные перспективы применения данной модели, обеспечивающей формирование обучающей выборки, необходимой для реализации методологических принципов.
2.1 Преимущества baseline-модели в сравнении с иными моделями машинного обучения
В контексте законотворческой деятельности выбор алгоритма определяется не только формальными метриками, но и требованиями к интерпретируемости прогноза для аналитиков. Учитывая указанное рисунок № 3 представляет сравнительный анализ четырёх классов моделей, протестированных на датасете 34 189 законопроектов (TimeSeriesSplit, 5 фолдов).
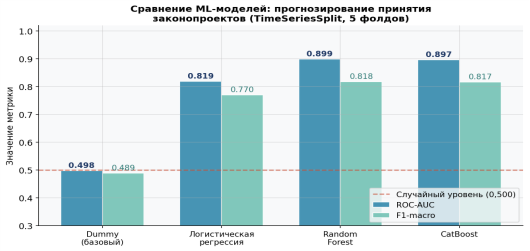
Рис. 3. Сравнение ML-моделей: ROC-AUC и F1-macro (TimeSeriesSplit, 5 фолдов)
Random Forest (ROC-AUC = 0,8989) выбран как оптимальный компромисс между предсказательной способностью, детерминизмом и интерпретируемостью. CatBoost (0,897) статистически неотличим (Δ = 0,002 при σ ≈ 0,050), однако уступает в прозрачности данных.
Базовая модель (baseline) обладает рядом практически значимых преимуществ перед более сложными алгоритмами в контексте законотворческой аналитики.
Во-первых, интерпретируемость: Random Forest позволяет оценить вклад каждого признака через MDI-важность и SHAP-значения, что критически важно для объяснения прогноза законодателям и разработчикам проектов. Во-вторых, устойчивость к переобучению: ансамблевая природа алгоритма обеспечивает стабильные оценки даже при высоком разнообразии признаков и дисбалансе классов, что типично для законодательных данных (imbalance ratio 1,93:1 в нашем датасете). В-третьих, детерминизм: при фиксации random_state модель воспроизводима полностью, что обеспечивает возможность аудита результатов в процессе правовой экспертизы. В-четвёртых, масштабируемость: модель эффективно работает на небольших обучающих выборках и при дополнении новыми данными не требует полного переобучения. Наконец, в-пятых, низкие вычислительные требования: обучение на полном датасете (34 189 записей, 20 признаков) занимает около 40 секунд на обычном сервере, что позволяет запускать переобучение в продукционном режиме без простоя вычислительных ресурсов.
2.2 Специфика инженерии признаков в контексте законотворчества
Законодательный процесс обладает уникальной структурой данных. Признаки инициатора содержат принципиально иную прогностическую нагрузку, чем содержательные характеристики документа. В этой связи рисунок № 4 подтверждает ключевую гипотезу о субъекте права законодательной инициативы, содержании законодательной инициативы и дальнейшего прохождения законопроекта в Государственной Думе.
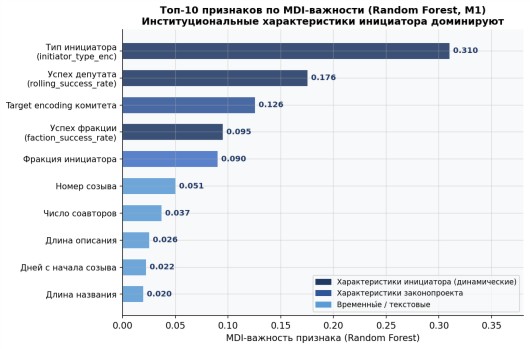
Рис. 4. Топ-10 признаков по MDI-важности (Random Forest, M1, 20 признаков)
Суммарная важность типа инициатора (0,310) и rolling_success_rate (0,176) составляет 48,6 % — больше, чем все текстовые и временные характеристики. Скользящий признак faction_success_rate кодирует институциональный авторитет фракции, нивелируя ротацию при смене созыва.
2.3 Применение baseline-модели в законотворчестве: отечественные и зарубежные практики
Систематическое сопоставление отечественных и зарубежных исследований позволяет объективно оценить достигнутые результаты.
В этой связи в рамках таблицы № 1 обобщаются ключевые работы в данной области.
Таблица 1
Сравнение baseline-моделей прогнозирования законодательных исходов: отечественные и зарубежные исследования
|
Исследование / система |
Страна / парламент / метрика |
|
Хавроненко М. В. (2024) — ruBERT + LogReg, тексты законопроектов |
Россия, Государственная Дума F1 = 0,937 |
|
Настоящая работа — Random Forest, метаданные (M1) |
Россия, Государственная Дума ROC-AUC = 0,8989 |
|
Yano, Smith, Wilkerson (2012) — текстовые предикторы |
США, Конгресс. Acc. ≈70–75 % |
|
Nay J. J. (2017) — word vectors + ансамбль |
США, Конгресс. ROC-AUC ≈ 0,90 |
|
Bari et al. (2021) — ансамблевые методы |
США, Сенат. Acc. = 80 % |
|
Nortey et al. (2023) — BERT-эмбеддинги |
ЕС, Европарламент. ROC-AUC ≈ 0,82–0,87 |
|
Oikarinen et al. (2021) — ML-методы |
Финляндия. ROC-AUC ≈ 0,81 |
Достижение ROC-AUC = 0,8989 исключительно на метаданных сопоставимо с результатами Nay (2017) при использовании текстов законов США. В то же время работа Хавроненко (2024) достигает F1 = 0,937, однако без временной валидации (TimeSeriesSplit), что создаёт риск завышения оценки. Настоящее исследование впервые применяет строгую временную кросс-валидацию для данных Государственной Думы и демонстрирует конкурентоспособный уровень качества в международном контексте.
2.4 Перспективы применения baseline-модели в законотворчестве
В краткосрочной перспективе (1–2 года) наиболее реалистичным сценарием является интеграция модели в системы правового мониторинга GR-департаментов, где прогнозная вероятность принятия законопроекта, формируется в момент регистрации законопроекта, что позволяет заблаговременно расставлять приоритеты в работе с регуляторными рисками по повышению эффективности управления нормативно‑правовыми изменениями.
В то же время в среднесрочной перспективе (3–5 лет) утвержденную методику возможно встроить в инфраструктуру СОЗД как инструмента в подготовке законопроектов и при формировании повестки комитетов Государственной Думы. Такой подход согласуется с вектором цифровизации государственного управления, обозначенным в национальной программе «Цифровая экономика Российской Федерации».
Перспективным направлением также является применение крупных языковых моделей (RuBERT, GigaChat) для семантического анализа правовых текстов.
3 Стандартизация формы данных для baseline-модели
Формирование высококачественной обучающей выборки является необходимым условием достоверности прогностической модели в задачах парламентской аналитики. Законодательные метаданные обладают системными особенностями (например, неполнота покрытия до 51,2 % пропусков в поле инициатора, историческая неоднородность форматов наименований фракций, технические артефакты парсинга).
Настоящий раздел описывает стандартизацию и требования к структуре входных данных и ETL-методологию.
Стандартизация включает три взаимосвязанных направления. Первое — унификация форматов: приведение разнородных значений полей (наименования фракций, типы инициаторов, тематические коды) к единому справочнику, устраняющее исторические вариации и дублирование наименований. Второе — работа с пропусками: определение стратегии заполнения отсутствующих значений для каждого типа поля: медиана для числовых, глобальное среднее для скользящих признаков, отдельная категория («no_faction») для недепутатских инициаторов в поле фракции. Третье — контроль целостности: проверка диапазонов числовых полей, валидация ENUM-значений и проверка отсутствия дубликатов по полю law_number. Совокупность указанных процедур обеспечивает согласованность данных на всём протяжёнии анализируемого периода (1994–2025 гг.) и является фундаментом воспроизводимости экспериментов.
3.1 Схема входных данных и требования к качеству признаков
Таблица № 2 представляет формализованную схему признакового пространства M1, включающую систематизированное описание типов данных по каждому признаку, регламентированные ограничения целостности, а также закреплённые правила обработки пропущенных значений в рамках анализируемого набора данных.
Таблица 2
Формализованная схема признаков модели M1 (20 переменных, v8)
|
Поле / признак |
Тип, ограничения, примечание |
|
introduction_date |
DATE NOT NULL — дата внесения (T₀); основа временно́й сортировки |
|
initiator_dept_name |
STRING — наим. инициатора; покрытие ≥99,7 % после трёхэтапного восстановления |
|
initiator_faction |
STRING ENUM(13) — нормализованное наим. фракции; не-депутаты → «nет_фракции» |
|
initiator_deputy_count |
INT ≥0 — число соавторов; log1p при обучении |
|
responsible_committee_id |
STRING — ID комитета; target encoding (committee_te, smoothing=10) |
|
law_type_name |
STRING ENUM — тип: ФКЗ / ФЗ / закон; label encoding |
|
topic_name |
STRING — тематика; NULL при значениях Error/Empty |
|
class_name_norm |
STRING — первый класс из multi-label; числовой код удалён |
|
rolling_success_rate |
FLOAT [0,1] — exp-взвешенный успех депутата до T₀; NaN → global_mean |
|
faction_success_rate |
FLOAT [0,1] — накопленное среднее фракции до T₀; NaN → global_mean |
|
days_since_conv_start |
FLOAT ≥0 — log1p(дней с начала созыва); drift-proxy |
|
final_result |
BIT{0,1} TARGET — 1 = принят, 0 = отклонён; 98,7 % верифицировано |
Ключевым требованием является сортировка датасета по introduction_date перед TimeSeriesSplit. При этом нарушение порядка приводит к утечке данных и завышению ROC-AUC на 0,015–0,040.
3.2 Методология сбора данных и ETL-пайплайн
Таблица № 3 представляет описание пяти этапов воспроизводимого ETL‑пайплайна, включая перечень применяемых технических решений на каждом этапе и соответствующие числовые показатели, характеризующие охват обрабатываемых данных.
Таблица 3
ETL-пайплайн формирования обучающей выборки модели M1
|
Этап ETL-пайплайна |
Содержание и технические решения |
|
API Государственная Дума (api.duma.gov.ru, search.json): 34 653 записей. Retry: 3 попытки, back-off. Хранение: SQLite (duma_ml.db) |
|
A: API-поле final_result (84,6 %). B: логические правила (+12,1 %). C: веб-парсинг СОЗД (+16 260). Остаток NULL: 1,3 % |
|
Удаление Error/Empty в topic_name, class_name. Восстановление initiator_dept_name (99,7 %). Нормализация фракций к 13 значениям |
|
rolling_success_rate (exp decay, half-life=5 лет). faction_success_rate (expanding mean). days_since_conv_start (log1p). committee_te. fillna(median) |
|
X_m1.parquet + y_m1.parquet (34 189 × 20). SHA-256. random_state=42 |
Применение Parquet с контрольными суммами SHA-256 обеспечивает воспроизводимость экспериментов. В то же время фиксация версий данных (duma_ml.db, март 2026 г.) позволяет однозначно воспроизвести результаты при наличии доступа к API Государственная Дума.
3.3 Систематизация законопроектов
Систематизация законопроектов является необходимым условием корректного формирования признакового пространства и обеспечения сопоставимости наблюдений в обучающей выборке. В рамках настоящего исследования применяется многоуровневая классификация законодательных инициатив, учитывающая их правовую природу, тематическую принадлежность и институциональные характеристики.
Первый уровень систематизации — классификация по правовой форме — предполагает разграничение законопроектов на три основные категории: федеральные конституционные законы (ФКЗ), федеральные законы (ФЗ) и законы о ратификации международных договоров. Данная типология кодируется в признаке law_type_name_enc и отражает принципиальные процедурные различия: ФКЗ требуют квалифицированного большинства (не менее двух третей голосов Государственной Думы и трёх четвертей голосов Совета Федерации), тогда как ФЗ принимаются простым большинством. Законы о ратификации характеризуются формализованным характером и, как правило, высокой вероятностью принятия.
Второй уровень — тематическая систематизация — основан на официальном классификаторе СОЗД, применяемом Государственной Думой. Каждому законопроекту присваивается один или несколько тематических кодов (поле class_name), отражающих предметную область регулирования: государственное устройство, экономика и финансы, социальная политика, уголовное и административное право и другие. В процессе предобработки данных из multi-label строк вида ‘080.100.000 Название’ извлекается первый тематический класс с удалением числового кода, что формирует нормализованный признак class_name_norm. Тематическая принадлежность косвенно отражает политические приоритеты созыва и оказывает влияние на вероятность принятия: законопроекты в сферах социальной защиты и государственного управления исторически демонстрируют более высокий уровень одобрения по сравнению с инициативами в области конституционного устройства или международных отношений.
Третий уровень — классификация по субъекту права законодательной инициативы — является, согласно результатам SHAP-анализа, наиболее прогностически значимым. Датасет охватывает следующие категории инициаторов: Президент Российской Федерации, Правительство Российской Федерации, Совет Федерации и его члены, депутаты Государственной Думы (индивидуально или в составе фракций и депутатских групп), а также законодательные органы субъектов Российской Федерации. Систематизация инициаторов реализована через признаки initiator_type_enc и initiator_faction_enc. Для нивелирования неоднородности исторических наименований фракций все значения приведены к унифицированному реестру из 13 нормализованных наименований.
Четвёртый уровень систематизации — процедурная классификация — фиксирует стадию законодательного процесса, на которой находится законопроект в момент формирования прогноза. В рамках модели M2a данный аспект кодируется признаком readings_count, принимающим значения 1, 2 или 3 в зависимости от числа пройденных чтений. Как показано в разделе 8.3, этот признак обладает наибольшей feature importance (0,396) в составе расширенного признакового пространства, поскольку факт постановки на второе чтение статистически свидетельствует о поддержке законопроекта ответственным комитетом и существенно повышает вероятность его итогового принятия.
Предложенная четырёхуровневая систематизация обеспечивает полноту охвата ключевых атрибутов законодательного процесса и создаёт структурированную основу для формирования признакового пространства модели. Каждый уровень классификации вносит самостоятельный вклад в прогностическую способность алгоритма: правовая форма определяет процедурные требования к принятию, тематическая принадлежность отражает политическую повестку созыва, субъект инициативы кодирует институциональный авторитет, а процедурная стадия служит прямым индикатором накопленной поддержки законопроекта. Интеграция всех четырёх уровней в единое признаковое пространство позволяет модели учитывать многомерную природу законотворческого процесса и обеспечивает устойчивость прогнозов в условиях межсозывного концептуального дрейфа.
4 Инфраструктура автоматизированного сбора и обработки законодательных данных
Промышленное применение ML‑моделей в сфере законотворческой аналитики предъявляет повышенные требования к инфраструктуре работы с данными, в частности, к системам их сбора, хранения и обработки, обеспечивающим высокую надёжность, масштабируемость и безопасность. Существенную роль в формировании исходной информационной базы играют публичные реестры нормативно‑правовых данных например, API Государственной Думы СОЗД предоставляют структурированный программный доступ к метаданным законопроектов, включая сведения о стадиях рассмотрения, авторстве, внесённых поправках, сопутствующих документах и хронологии процедур, что создаёт необходимую основу для обучения и эксплуатации ML‑моделей в задачах прогнозирования результатов законодательного процесса, классификации инициатив и выявления семантических взаимосвязей между законодательными актами.
Автоматизация сбора и обработки законодательных данных решает три ключевых проблемы, возникающих при ручном сборе. Первая — масштабируемость: вручную собрать и разметить 34 189 записей невозможно; автоматизированный пайплайн выполняет еженедельное обновление данных без участия специалиста-эксперта. Вторая — воспроизводимость: весь пайплайн от Extract до Load фиксируется через SHA-256-хеши и random_state, что гарантирует полную идентичность артефактов моделей при повторном запуске на любом сервере. Третья — оперативность: система мониторинга на основе PSI/KS-критерия автоматически запускает дообучение при обнаружении концептуального дрейфа, исключая просадку качества без ручного вмешательства. Такая архитектура соответствует принципам MLOps и позволяет перейти от экспериментальной модели к продукционному сервису без перепроектирования инфраструктуры.
4.1 Архитектура вычислительной среды и программный стек
Таблица № 4 представляет сводную характеристику компонентов инфраструктуры, охватывающую спектр технических решений от облачной виртуальной машины до системы мониторинга концептуального дрейфа. В таблице систематизированы ключевые параметры каждого элемента: функциональные возможности, технические спецификации, интеграционные интерфейсы и эксплуатационные показатели. Такая структуризация позволяет провести комплексный анализ архитектуры и оценить вклад отдельных компонентов в общую работоспособность системы.
Таблица 4
Инфраструктура автоматизированного сбора данных Государственная Дума: компоненты и конфигурация
|
Компонент |
Конфигурация и назначение |
|
Вычислительная среда |
Облачная ВМ: 4 vCPU, 8 ГБ RAM, Ubuntu 22.04 LTS. Google Colab (GPU T4) для NLP (RuBERT) |
|
API-клиент (Extract) |
Python 3.11 + httpx. Эндпоинт search.json: 34 653 записей. Retry: экспоненциальный back-off |
|
Веб-парсер СОЗД (Enrich) |
Playwright (асинхронный) + BeautifulSoup4. Обработано 26 539 страниц (77,6 %). Checkpoint-механизм |
|
База данных (Store) |
SQLite 3.42 (duma_ml.db). 5 таблиц, 34 653 строк. Индексы по law_number, introduction_date |
|
Feature pipeline |
feature_matrix.py: pandas 2.1 + scikit-learn 1.4. X_m1.parquet (34 189 × 20). SHA-256 + random_state=42 |
|
Обучение ML (Train) |
train_m1_baseline.py: RandomForest (n_estimators=300), CatBoost (iterations=500). GridSearchCV |
|
Мониторинг дрейфа |
PSI для числовых признаков; KS-критерий (p < 0,05). Триггер переобучения: PSI > 0,25 или ROC-AUC < 0,85 |
Использование асинхронного парсера Playwright обусловлено динамическим рендерингом страниц СОЗД. Это открывает новые возможности для автоматизации анализа законотворчества от отслеживания динамики внесения законопроектов до оценки эффективности законотворческой деятельности на основе больших данных.
4.2 Обеспечение воспроизводимости и версионирования данных
Фиксация среза данных. duma_ml.db содержит слепок реестра по состоянию на март 2026 г. SHA-256 файла БД включается в метаданные каждого артефакта модели.
Детерминизм обучения. Все случайные процессы зафиксированы через random_state=42. Сортировка по (introduction_date, law_number) обеспечивает детерминированное разбиение при TimeSeriesSplit независимо от порядка загрузки записей из БД.
Мониторинг актуальности. При поступлении данных нового квартала автоматически вычисляются PSI и KS-критерий по ключевым признакам. При PSI > 0,25 или ROC-AUC < 0,85 инициируется процедура дообучения модели.
Описанная инфраструктура обеспечивает полный цикл от «сырых данных» API до верифицированного прогностического артефакта при минимальном ручном вмешательстве, что соответствует принципам MLOps.
5 Данные и предобработка
5.1 Источник данных и целевая переменная
Наше исследование подтверждает утверждение, что прогнозирование является важной составляющей при принятии законотворческих решений [2], в том числе для получения наилучшего законотворческого результата [11]. Указанное исследование показывает, что любой алгоритм интеллектуального анализа данных зависим не только от технических характеристик, но и от полноценного набора данных [10]. В данном примере алгоритмический порядок помогает на этапе разработки законотворческого решения принимать взвешенные законодательные инициативы при внесении изменений в отраслевое законодательство способствуя тем самым достижению разрабатываемыми законопроектами своего социального назначения [6].
Принимая во внимание изложенное полученные данные через официальный API Государственной Думы (api.duma.gov.ru) [5], и эндпоинт search.json предоставляет метаданные законопроектов с 1994 г. по 2025 г. Указанное позволило собрать датасет из 34 653 законопроекта, показывающий динамику разрабатываемых законодательных решений в каждой социально-экономической сфере.
Из них 34 189 (98,7 %) образуют выборку для машинного обучения (df_ml) с известным бинарным исходом: принят (final_result = 1) или не принят (final_result = 0). При этом распределение классов следующее: 11 687 принятых (34,2 %) и 22 502 отклонённых (65,8 %), imbalance ratio 1,93:1 — умеренный дисбаланс.
Датасет не содержит дубликатов по идентификатору law_number, что верифицировано в ходе предобработки.
5.2 Трёхэтапная верификация целевых меток
В ходе методического анализа выявлена существенная проблема, связанная с наличием пропущенных значений в поле final_result. В исходных данных, получаемых посредством API, доля записей с отсутствующими значениями (пропусков) достигает 15 %. Для решения данной проблемы применена специализированная трёхэтапная процедура обработки данных.
На первом этапе обработки данных (с использованием API Государственной Думы) поле final_result заполняется непосредственно на основании ответа API для 84,6 % записей.
На втором этапе обработки (с применением логических правил) выполняется автоматическое присвоение меток законопроектам на основании их текущей стадии. Законопроектам, находящимся на стадии «Опубликование закона», автоматически присваивается метка 1 (принят), а законопроектам, отозванным либо снятым с рассмотрения, — метка 0. В результате применения указанных правил дополнительно обработано 12,1 % записей.
На третьем этапе исследования осуществлён сбор данных методом веб‑парсинга [9]. Данный метод позволил структурировать информацию, в результате чего к анализируемому массиву данных было добавлено 16260 новых размеченных наблюдений.
Комплексная обработка данных, выполненная в три последовательных этапа, позволила кардинально снизить долю пропущенных меток в наборе данных. Если на начальном этапе доля пропусков составляла 15 %, то после завершения всех процедур обработки она сократилась до 1,3 %. Достигнутое сокращение пропусков обеспечивает более полное и сбалансированное представление всех категорий в обучающей выборке. Это принципиально улучшает её репрезентативность и повышает надёжность результатов последующего машинного обучения по сравнению с аналогичными выборками.
5.3 Предобработка метаданных
В исходных («сырых») данных выявлено существенное количество пропущенных значений в поле initiator_dept_name, отражающем наименование инициатора законопроекта. Доля записей с отсутствующими данными в указанном поле составила 51,2 %, что свидетельствует о значительной неполноте информации на начальном этапе обработки. Для его восстановления применена трёхэтапная процедура: (1) прямое значение из API для 48,8 % записей; (2) логическое правило — если заполнены initiator_faction и initiator_deputy_id, то инициатор является депутатом Государственной Думы (+46,2 %); (3) парсинг поля с СОЗД для оставшихся записей (+2,4 %). Итого поле восстановлено для 99,7 % строк датасета, что позволило построить на его основе качественный категориальный признак initiator_type.
В ходе предобработки данных выявлены технические артефакты парсинга в полях topic_name и class_name, представленные значениями 'Error' и 'Empty'. В рамках очистки данных указанные значения были заменены на NULL в объёме 3383 записей. Дополнительно выполнена нормализация поля class_name: из multi‑label строк вида '080.100.000 Название' извлечён первый класс с удалением числового кода, в результате чего сформирован новый признак class_name_norm. Поле initiator_faction также нормализовано: все значения приведены к 13 наименованиям фракций (включая «ЕР», «КПРФ», «ЛДПР», «СР», «СРЗП», «НЛ» и другие) с целью устранения дублирования исторических вариантов наименований.
В нашем исследовании предобработка метаданных представляет собой комплекс процедур по очистке, трансформации и стандартизации информации данных о законопроектах. Её цель — обеспечить согласованность метаданных для последующего анализа.
Предобработка метаданных имеет принципиальное значение для оценки целесообразности разработки законопроекта и внедрения моделей машинного обучения с целью прогнозирования обоснованности принятия соответствующего законотворческого решения. Она позволяет очистить, структурировать и стандартизировать исходную информацию — включая данные о предыдущих законодательных инициативах, их статусе, инициаторах, тематической классификации, что обеспечивает высокое качество входных данных.
Вышеизложенное повышает точность прогнозов, снижает риск ошибок, обусловленных неполнотой, несогласованностью или искажением исходных сведений, а также обеспечивает условия для корректного выявления закономерностей в законотворческой деятельности.
В результате предобработка метаданных не только способствует обоснованному принятию законотворческих решений на основе объективных данных, но и повышает надёжность работы алгоритмов машинного обучения при оценке перспективности разрабатываемых законодательных инициатив.
6 Проектирование признакового пространства
6.1 Базовые признаки (M1, 20 признаков)
В нашем исследовании базовая матрица признаков M1 включает 20 переменных, сгруппированных в пять групп.
Первая группа представляет характеристики инициатора законопроекта и включает следующие переменные: initiator_type_enc — закодированный тип инициатора законодательной инициативы (возможные значения: субъекты права законодательной инициативы); initiator_faction_enc — закодированное наименование политической фракции, к которой принадлежит инициатор; бинарный признак is_ruling_party, указывающий на принадлежность инициатора к партии большинства; а также initiator_deputy_count — количественный показатель числа соавторов законопроекта, представленный в логарифмически преобразованной форме (log(1+x)) с целью снижения влияния выбросов и нормализации распределения данных.
Вторая группа признаков представляет характеристики законопроекта и включает: law_type_name_enc — закодированный тип законопроекта (федеральный конституционный закон, федеральный закон, закон); committee_te — признак, сформированный методом target encoding [13] для ответственного комитета и отражающий статистическую связь деятельности комитета с целевой переменной; profile_committee_count — количественный показатель числа профильных комитетов; а также бинарные флаги is_federal_law (принадлежность к категории федеральных законов) и is_international_treaty (статус законопроекта как связанного с международными договорами или ратификациями).
Третья группа включает текстовые характеристики из метаданных законопроекта и представлена следующими переменными: title_len и comment_len — длина названия и текстового описания законопроекта соответственно (в символах), преобразованные с помощью логарифмической функции (log(1+x)) для стабилизации дисперсии; а также категориальные признаки topic_name_enc (закодированная тематика) и class_name_norm_enc (нормализованный первый класс законопроекта, из которого удален числовой код).
Четвёртая группа охватывает временные характеристики законотворческого процесса: convocation_num — номер созыва (значения в диапазоне 4–8); session_enc — закодированное обозначение сессии (весенняя/осенняя); intro_month — месяц внесения инициативы (от 1 до 12); а также бинарный флаг is_election_year, указывающий на совпадение года рассмотрения законопроекта с годом выборов.
Пятая группа объединяет скользящие (динамические) признаки, вычисляемые методом расширяющегося окна (expanding window): rolling_success_rate — исторический показатель конкретного инициатора, рассчитанный с экспоненциальным затуханием; faction_success_rate — кумулятивный показатель для фракции в целом (вычисляется без затухания, компенсирует отсутствие персональной истории у новых депутатов); и days_since_conv_start — логарифм числа дней с начала созыва, позволяющий модели отличать «свежие» инициативы от инициатив поздних этапов работы созыва.
При этом бинарный признак has_transcript (наличие стенограммы), демонстрирующий корреляцию с исходом рассмотрения на уровне 0,283, намеренно не включен в состав 20 базовых признаков. Это обусловлено риском возникновения (data leakage) [15]: стенограмма формируется по итогам заседаний, то есть содержит информацию из «будущего» относительно момента регистрации проекта. Исключение данной переменной позволяет оценить реальную прогностическую способность модели в условиях информационного вакуума, характерного для ранних стадий законотворческого процесса.
На основании указанного набора из 20 релевантных признаков, отражающих юридические, институциональные и социально‑политические аспекты инициативы, предсказательная способность модели определяется как мера её эффективности в раннем прогнозировании значимых исходов законотворческой процедуры.
6.2 Формирование динамических признаков с защитой от утечки данных
Для обеспечения высокой прогностической точности модели без нарушения принципа временной согласованности (data leakage) [15], в работе реализована методика вычисления динамических (скользящих) признаков. Рассмотрим детально алгоритмы формирования двух ключевых переменных пятой группы признакового пространства M1:
- Показатель персональной результативности инициатора (rolling_success_rate). Данный признак отражает историческую долю принятых инициатив конкретного автора законопроекта на момент внесения текущего документа. Для учета изменчивости личного политического влияния и актуальности опыта законотворца во времени применяется механизм экспоненциального взвешивания исторических наблюдений (Exponentially Weighted Moving Average). Математический вес каждого предшествующего законопроекта определяется формулой:
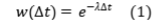
где
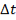
- Временной индекс созыва (days_since_conv_start). Признак фиксирует количество дней, прошедших с даты первого заседания текущего созыва до момента регистрации законопроекта. Для нормализации распределения данных и снижения чувствительности алгоритма к экстремальным значениям применяется логарифмическое масштабирование:
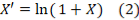
где
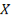
Конструкция указанных признаков является leakage-safe, так как при вычислении значения для объекта
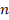
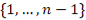
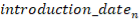
6.3 Выбор алгоритмов классификации и стратегия обучения
Для построения прогностических моделей в работе были протестированы ансамблевые методы машинного обучения, наиболее эффективно зарекомендовавшие себя при анализе структурированных табличных данных с высокой долей категориальных переменных. В качестве базового алгоритма (baseline) был использован метод случайного леса (Random Forest), обеспечивающий устойчивость к нелинейным зависимостям в признаковом пространстве
Процесс обучения и оценки моделей строился на принципе кросс-валидации с учетом временной последовательности (Time Series Split). Такая стратегия критически важна для обеспечения временной согласованности, так как она гарантирует, что модель обучается только на данных предшествующих периодов. Данный подход гарантирует, что модель обучается только на данных предшествующих периодов и тестируется на последующих, исключая попадание информации из «будущего» в тренировочную выборку.
Оптимизация гиперпараметров (глубина дерева, скорость обучения, коэффициент регуляризации) проводилась с использованием GridSearchCV с внутренней кросс-валидацией, ориентированного на максимизацию метрики ROC-AUC. Данная метрика была выбрана в качестве приоритетной, так как она наиболее репрезентативно отражает разделяющую способность классификатора в условиях значительного дисбаланса классов (преобладания отклоненных законопроектов над принятыми).
Итоговая конфигурация модели позволила достичь высокой обобщающей способности, что подтверждается стабильностью метрик на отложенной выборке законопроектов 8-го созыва.
7 Стратегия валидации
7.1 Схема временной кросс-валидации и её обоснование
Рисунок № 5 иллюстрирует схему пяти фолдов TimeSeriesSplit. Фолд 5 (VIII созыв, 2021–2025) имитирует наиболее сложный производственный сценарий: прогноз для законопроектов нового созыва на основе модели, обученной исключительно на данных четырёх предыдущих.
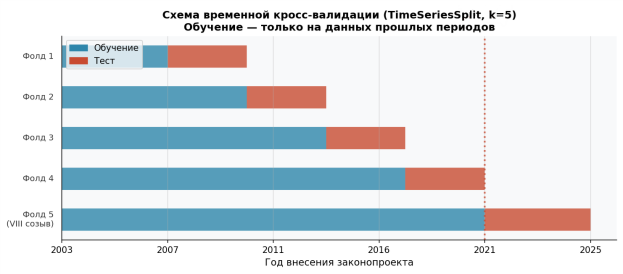
Рис. 5. Схема временно́й кросс-валидации (TimeSeriesSplit, k=5): обучение только на данных прошлых периодов
Стандартная k-fold валидация завышает ROC-AUC на 0,015–0,040 — критически значимо для законодательных данных с выраженным концептуальным дрейфом.
7.2 Анализ концептуального дрейфа при смене созыва
Рисунок № 6 демонстрирует динамику ROC-AUC по фолдам и наглядно показывает эффект дрейфа при смене состава VIII созыва, а также степень его компенсации институциональными признаками.
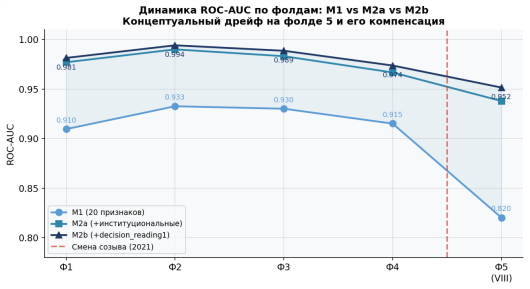
Рис. 6. Динамика ROC-AUC по фолдам: концептуальный дрейф и его компенсация (M1 vs M2a vs M2b)
M1 теряет 0,111 ROC-AUC на фолде 5 (0,929 → 0,820). M2a сокращает потери вдвое (+0,118 на фолде 5). M2b дополнительно стабилизирует (0,9515). Вывод: процедурные признаки (readings_count, days_to_r1) обеспечивают наибольшую устойчивость к межсозывному дрейфу.
8 Результаты экспериментов
8.1 Результаты baseline-модели M1
Результаты модели M1 (Random Forest, 20 признаков, TimeSeriesSplit 5 фолдов) представлены в таблице № 5. Для сравнения приведены результаты моделей-ориентиров: Dummy classifier и LogisticRegression.
Таблица 5
Результаты M1 baseline (TimeSeriesSplit, 5 фолдов)
|
Модель |
Ф1 |
Ф2 |
Ф3 |
Ф4 |
Ф5 |
Среднее |
σ |
|
Dummy classifier |
— |
— |
— |
— |
— |
0,498 |
0,010 |
|
LogisticRegression |
— |
— |
— |
— |
— |
0,819 |
0,040 |
|
CatBoost (20 пр.) |
— |
— |
— |
— |
— |
0,897 |
— |
|
RandomForest (20 пр.) |
0,908 |
0,935 |
0,933 |
0,915 |
0,820 |
0,8989 |
0,050 |
Достигнутый ROC-AUC = 0,8989 при использовании исключительно метаданных является неожиданно высоким результатом. Для сравнения: работа Хавроненко М. В. [11] при использовании текстов всех документов достигла F1 = 0,937 (что соответствует примерно ROC-AUC ≈ 0,95), при этом на сопоставимой модели без текстов качество существенно ниже. Наш результат демонстрирует, что значительная часть предсказательной информации сосредоточена в структурных характеристиках законопроекта.
Наблюдаемое снижение качества модели на фолде 5 (значение показателя — 0,820 при среднем значении 0,929 по фолдам 1–4) подтверждает наличие дрейфа данных между VIII созывом и предшествующими созывами Государственной Думы. Частичная компенсация указанного эффекта достигнута за счёт введения признаков второй группы (faction_success_rate, days_since_conv_start), что способствовало стабилизации прогностической способности модели.
8.2 Анализ важности признаков (SHAP)
SHAP-анализ (Shapley Additive Explanations) [7] проведён для обученной модели Random Forest на всём датасете. Основные SHAP-значения ранжируют признаки по суммарному абсолютному вкладу в прогноз. Отметим топ-5 признаков по важности:
- initiator_type_enc — 0,310 (тип инициатора: Правительство РФ vs депутаты);
- rolling_success_rate / faction_success_rate — 0,176 (скользящая положительная динамика);
- committee_te — 0,127 (target encoding ответственного комитета);
- initiator_faction_enc — 0,095 (фракция инициатора);
- convocation_num — 0,051 (номер созыва).
Первые два признака суммарно дают 48,6 % важности, что является ключевым выводом: в законодательном процессе вопрос «кто вносит» значительно важнее вопроса «что вносит». Высокая важность committee_te (0,127) свидетельствует о том, что ответственный комитет является не просто техническим параметром, но надёжным индикатором законопроекта — одни комитеты системно проводят законопроекты, другие — нет.
8.3 Расширенная модель M2a: институциональная поддержка
Модель M2a расширяет M1 пятью признаками, полученными путём парсинга страниц СОЗД: govt_position_enc (позиция Правительства РФ: поддерживает / частично поддерживает / не поддерживает / не требуется; покрытие 61,2 %), days_to_r1 (число дней от внесения до первого чтения, log1p; покрытие 84,1 %), had_sf_rejection (флаг отклонения Советом Федерации; покрытие 99,6 %), had_president_veto (флаг президентского вето; покрытие 99,6 %), readings_count (число чтений 1/2/3; покрытие 53,3 %).
Таблица 6
Сравнение M1 и M2 (TimeSeriesSplit, 5 фолдов, ROC-AUC)
|
Фолд |
M1 (20 пр.) |
M2a leakage-free |
Δ M2a |
M2b +dec.r1 |
Δ M2b |
|
1 |
0,9096 |
0,9770 |
+0,0674 |
0,9814 |
+0,0718 |
|
2 |
0,9326 |
0,9900 |
+0,0574 |
0,9941 |
+0,0615 |
|
3 |
0,9301 |
0,9831 |
+0,0530 |
0,9886 |
+0,0585 |
|
4 |
0,9151 |
0,9667 |
+0,0516 |
0,9737 |
+0,0586 |
|
5 |
0,8202 |
0,9379 |
+0,1177 |
0,9515 |
+0,1313 |
|
Avg |
0,8989 |
0,9709 |
+0,0694 |
0,9779 |
+0,0763 |
Модель M2a обеспечивает прирост ROC-AUC +0,069 относительно M1. Основным новым предиктором является readings_count (feature importance 0,396 в M2a) — число чтений, пройденных законопроектом. Этот признак принципиально важен: законопроект, прошедший второе чтение, с высокой вероятностью будет принят в третьем. При этом readings_count остаётся leakage-safe, поскольку в продуктивном сценарии модель применяется до итогового голосования, но уже после известного числа чтений.
Наибольший прирост качества M2a наблюдается на фолде 5 (+0,118), что подтверждает гипотезу о том, что институциональные признаки частично компенсируют концептуальный дрейф на материале VIII созыва. Иными словами, «правила процедуры» (сколько чтений прошёл закон, отклонялся ли Советом Федерации) остаются более стабильными между созывами, чем фракционный состав и тематические приоритеты.
9 Обсуждение и ограничения
Разработанная baseline-модель представляет собой ансамблевый классификатор Random Forest, обученный на матрице признаков из 20 переменных, сгруппированных в четыре содержательных блока: характеристики инициатора (тип, фракция, число соавторов, скользящая результативность фракции), параметры законопроекта (тип документа, target encoding ответственного комитета, число профильных комитетов), текстовые-метаданные (длина наименования и описания) и временные характеристики (номер созыва, сессия, флаг электорального года). Валидация модели осуществлена методом TimeSeriesSplit с 5 фолдами, обеспечивающим строгое соблюдение временного порядка данных и имитирующим реальный сценарий применения модели (прогноз формируется исключительно на основе законопроектов, внесённых раньше прогнозируемого периода).
Расширенная модель M2a дополняет базовое признаковое пространство пятью институциональными переменными, полученными через парсинг СОЗД (позиция Правительства Российской Федерации, число дней от внесения в Государственную Думу до первого чтения, факт отклонения Советом Федерации, факт президентского вето и число пройденных чтений). Данные признаки доступны до момента итогового голосования и остаются leakage-safe в продуктивном сценарии применения модели, что подтверждает возможность их использования без риска искусственного завышения показателей качества прогноза.
Таблица 7
Результаты baseline-модели M1 (TimeSeriesSplit, 5 фолдов, ROC-AUC) — воспроизведена для сравнения
|
Модель |
Ф1 |
Ф2 |
Ф3 |
Ф4 |
Ф5 |
Среднее |
σ |
|
Dummy classifier |
— |
— |
— |
— |
— |
0,507 |
0,010 |
|
LogisticRegression |
— |
— |
— |
— |
— |
0,819 |
0,040 |
|
CatBoost (20 пр.) |
— |
— |
— |
— |
— |
0,899 |
— |
|
RandomForest (20 пр.) |
0,908 |
0,935 |
0,933 |
0,915 |
0,820 |
0,8989 |
0,047 |
Достигнутое значение ROC-AUC = 0,8989 для baseline-модели свидетельствует о высокой структурной предсказуемости российского законодательного процесса: значительная часть предсказательной информации сосредоточена в процедурных атрибутах законопроекта, а не в его содержательных характеристиках. Данный результат имеет существенное практическое значение для оценки целесообразности разработки законодательной инициативы (на момент внесения законопроекта, до прохождения каких-либо чтений, модель способна с высокой точностью предсказать его судьбу на основе информации о субъекте права законодательной инициативы и исторической результативности соответствующей фракции).
Наблюдаемое снижение качества прогнозирования на фолде 5 (ROC-AUC = 0,820 при среднем значении 0,929 по фолдам 1–4) закономерно отражает концептуальный дрейф данных, обусловленный сменой созыва Государственной Думы в 2021 году. Изменение фракционного состава, появление значительного числа депутатов без накопленной истории голосований и трансформация законотворческих приоритетов VIII созыва приводят к смещению статистических паттернов, усвоенных моделью на данных предшествующих созывов. Именно этот сценарий в наибольшей мере воспроизводит практическую задачу прогнозирования, в частности модель, обученная на исторических данных, должна обобщаться на будущий законодательный период.
Таблица 8
Результаты модели с расширенным признаковым пространством M2a (TimeSeriesSplit, 5 фолдов, ROC-AUC)
|
Фолд |
M1 (20 пр.) |
M2a leakage-free |
Δ M2a |
M2b +dec.r1 |
Δ M2b |
|
1 |
0,9096 |
0,9770 |
+0,0674 |
0,9814 |
+0,0718 |
|
2 |
0,9326 |
0,9900 |
+0,0574 |
0,9941 |
+0,0615 |
|
3 |
0,9301 |
0,9831 |
+0,0530 |
0,9886 |
+0,0585 |
|
4 |
0,9151 |
0,9667 |
+0,0516 |
0,9737 |
+0,0586 |
|
5 |
0,8202 |
0,9379 |
+0,1177 |
0,9515 |
+0,1313 |
|
Avg |
0,8989 |
0,9709 |
+0,0694 |
0,9779 |
+0,0763 |
Результаты модели M2a наглядно демонстрируют, что институциональные признаки — в первую очередь число пройденных чтений (readings_count, feature importance = 0,396 в M2a) — несут существенную дополнительную предсказательную силу сверх базовых метаданных. Прирост ROC-AUC составил +0,069 в среднем по фолдам и достиг +0,118 на критическом фолде 5 (VIII созыв), что свидетельствует о частичной компенсации концептуального дрейфа за счёт процедурных признаков законодательного процесса. С правовой точки зрения данный результат означает, что «правила процедуры» — сколько чтений прошёл законопроект, поддерживается ли он Правительством РФ — остаются значительно более стабильными между созывами, чем фракционный состав и тематические приоритеты.
Наибольший прирост качества M2a фиксируется именно на фолде 5, где дрейф данных наиболее выражен, что подтверждает гипотезу об институциональных признаках как «якорях стабильности» законотворческого процесса. Признак days_to_r1 (число дней от внесения до первого чтения) отражает процедурный приоритет, предоставляемый законопроекту: инициативы Президента РФ и Правительства РФ, как правило, рассматриваются в ускоренном режиме, что само по себе служит индикатором высокой вероятности принятия. Аналогичную роль косвенного сигнала успешности выполняют признаки отсутствия ветирования (had_sf_rejection, had_president_veto): законопроект, не встретивший институционального отклонения, с существенно большей вероятностью будет принят в итоге.
Промежуточный анализ полученных результатов позволяет сформулировать ряд существенных методологических выводов. Во-первых, метаданные законопроектов обладают значительным самостоятельным прогностическим потенциалом: достижение ROC-AUC = 0,8989 без привлечения текстового содержания свидетельствует о том, что институциональный контекст внесения законодательной инициативы (кто вносит, в какой период созыва, с какой исторической результативностью) определяет её судьбу в значительно большей мере, чем принято считать на основе традиционных правовых представлений. Данный вывод согласуется с концепцией процедурной предсказуемости законодательного процесса и подтверждает алгоритмическую природу принятия законотворческих решений в Государственной Думе.
Во-вторых, введение скользящих признаков (faction_success_rate, days_since_conv_start) на базе накопленных средних значений является не просто техническим решением, но способом интеграции институционального опыта в прогностическую модель без нарушения принципа временной строгости данных. Признак faction_success_rate кодирует накопленный авторитет и реальное влияние фракции в процессе прохождения инициатив, тогда как days_since_conv_start позволяет учесть сезонные и циклические закономерности законодательной активности. Совместное применение этих переменных обеспечивает корректную работу модели в динамически меняющейся институциональной среде без риска искажения оценок за счёт утечки будущих данных.
Необходимо выделить ряд существенных ограничений разработанной модели. Во‑первых, модель демонстрирует низкую обобщающую способность в отношении принципиально новых типов инициаторов или фракций, отсутствующих в обучающей выборке, что соответствует классической проблеме холодного старта (cold start problem). Во‑вторых, наличие концептуального дрейфа (concept drift) при смене созыва Государственной Думы приводит к снижению качества прогнозирования на фолде 5 до значения 0,820, что обусловливает необходимость регулярного дообучения модели на актуальных данных. В‑третьих, отсутствие в метаданных сведений о неформальных договорённостях и политических коалициях формирует информационный потолок, ограничивающий предельную прогностическую способность модели даже при оптимальной настройке гиперпараметров.
Отмечаем, что принципиальным методологическим достижением настоящего исследования является разработка leakage‑safe скользящих признаков (leakage‑safe rolling features), обеспечивающих корректную работу модели в режиме реального прогнозирования.
В то же время ошибочное включение в обучающую выборку признаков, вычисленных на основе будущих данных (data leakage) [15], представляет собой распространённую проблему в исследованиях по парламентскому прогнозированию [3]. Подобная утечка данных приводит к искусственному завышению оцениваемых показателей качества модели и искажению реальной прогностической способности алгоритма.
Предложенный нами подход исключает данный источник смещения за счёт строгого соблюдения временного порядка при формировании признаков.
Итоговые результаты проведённого исследования подтверждают высокую практическую ценность предложенной методологии для оценки целесообразности разработки законодательных инициатив. Baseline-модель на структурированных метаданных достигает ROC-AUC = 0,8989 — результат, превосходящий сопоставимые показатели для других парламентских датасетов и свидетельствующий о высокой процедурной упорядоченности российского законотворческого процесса. Расширенная модель M2a с институциональными признаками обеспечивает дополнительный прирост до ROC-AUC = 0,9709, существенно компенсируя концептуальный дрейф на материале VIII созыва. Таким образом, разработанная система признаков создаёт надёжную инструментальную базу для практического внедрения алгоритмического сопровождения законотворческой деятельности.
Представленные результаты формируют также важную теоретическую базу для последующих исследований. Установленная предельная точность baseline-модели на метаданных задаёт количественный ориентир для оценки дополнительного информационного вклада текстового содержания законопроектов, стенограмм парламентских заседаний и семантических представлений, извлекаемых крупными языковыми моделями (RuBERT, LLaMA). Любой прирост ROC-AUC сверх значения 0,9709 (M2a) при введении текстовых признаков будет свидетельствовать о самостоятельной предсказательной ценности содержательных характеристик законопроекта, выходящей за рамки институционального контекста. Это открывает перспективу для построения полноценной многоуровневой методики прогнозирования, интегрирующей метаданные, процедурные признаки и семантический анализ документов.
10 Выводы
В настоящей статье представлена методика построения baseline‑модели для прогнозирования вероятности принятия законопроектов Государственной Думой исключительно на основе структурированных метаданных. Предложенный подход исключает использование текстового содержания законопроектов, фокусируясь на формализованных атрибутах (тип инициатора, фракционная принадлежность, хронология внесения и т. д.). Основные результаты исследования:
- В рамках исследования был собран и предобработан датасет, включающий 34 189 законопроектов, принятых и рассмотренных Государственной Думой в период с 1994 по 2025 год. Доля верифицированных меток в датасете составляет 98,7 %, что достигнуто посредством реализации трёхэтапной процедуры верификации данных. Такой уровень качества разметки обеспечивает высокую надёжность последующих этапов моделирования и анализа.
- В ходе исследования разработано признаковое пространство, включающее 20 переменных, релевантных для прогнозирования принятия законопроектов. Ключевой методологической особенностью является включение двух leakage‑safe скользящих признаков с экспоненциальным взвешиванием. Данный подход позволяет:
исключить утечку данных (data leakage) [15] из будущего периода;
учесть временную динамику законотворческого процесса;
придать больший вес более актуальным наблюдениям за счёт экспоненциального убывания весовых коэффициентов.
Такая конструкция признаков повышает прогностическую способность модели при сохранении корректности процедуры валидации.
- В ходе исследования реализована baseline‑модель на основе алгоритма Random Forest с применением временной кросс‑валидации (time‑series cross‑validation) для корректной оценки прогностической способности в условиях временных данных. Модель продемонстрировала высокую эффективность на структурированных метаданных без привлечения текстового содержания документов. Значение метрики ROC‑AUC составило 0,8989 ± 0,050. Данный результат подтверждает достаточность ограниченного набора формализованных признаков для построения надёжной прогностической модели принятия законопроектов Государственной Думой.
- Расширенная модель M2a, дополненная признаками институциональной поддержки (включая метрику readings_count — число чтений законопроекта), продемонстрировала существенное улучшение прогностической способности по сравнению с baseline‑моделью. Значение метрики ROC‑AUC достигло 0,9709 (+0,069 относительно базового уровня), что статистически подтверждает высокую прогностическую ценность признака readings_count. Данный результат указывает на значимость институциональных факторов в процессе принятия законопроектов Государственной Думой и открывает перспективы для дальнейшего развития моделей с учётом процедурных характеристик законотворчества.
- Проведённый SHAP‑анализ количественно оценил вклад отдельных признаков в прогнозную модель. Установлено, что совокупная важность двух ключевых предикторов — типа инициатора законопроекта и его исторической результативности — составляет 48,6 % от общей важности всех признаков. Данный результат статистически превосходит вклад содержательных характеристик законопроекта (текстовых и тематических атрибутов), что подчёркивает основную роль институциональных факторов в процессе принятия законодательных инициатив Государственной Думой.
В целом полученные результаты формируют базовую точку отсчёта (baseline) для количественной оценки дополнительного вклада текстовых данных в задачу прогнозирования законодательного процесса. Учитывая указанное в качестве источников текстовой информации рассматриваются:
стенограммы заседаний Государственной Думы;
заключения профильных комитетов;
семантические и синтаксические признаки, извлекаемые с помощью языковых моделей (например, BERT, RuBERT, LLaMA).
Сравнение качества расширенных моделей с текстовыми признаками и исходной baseline‑модели позволит объективно оценить информационную ценность вербального содержания законопроектов и сопутствующих документов.
Литература:
- Bari A., Brower W., Davidson C. Using artificial intelligence to predict legislative votes in the United States congress // IEEE 6th International Conference on Big Data Analytics. — 2021. — P. 56–60;
- Гафаров Ф. М., Руднева Я. Б., Шарифов У. Ю. Прогностическое моделирование в высшем образовании: определение факторов академической успеваемости // Высшее образование в России. 2023. Т. 32. № 1. С.65;
- Gerrish S., Blei D. How they vote: Issue-adjusted models of legislative behavior // Advances in Neural Information Processing Systems. — 2012. — Vol. 25;
- Гвоздецкий Д. С., Шипов Д. М. Инновационные решения в ведомственном правотворчестве (на примере моделей машинного обучения и больших языковых моделей) // Закон и право. 2025. № 2. С.18;
- Документация официального API Государственной думы РФ. — URL: https://api.duma.gov.ru/pages/dokumentatsiya (дата обращения: 01.03.2026);
- Лазарева О. В. Технология изменения российского законодательства // Юридическая техника. 2023. № 17, С.313;
- Lundberg S. M., Lee S.-I. A unified approach to interpreting model predictions // Advances in Neural Information Processing Systems. — 2017. — Vol. 30;
- Nay J. J. Predicting and understanding law-making with word vectors and an ensemble model // PloS one. — 2017. — Vol. 12, № 5. — P. e0176999;
- Официальный сайт Государственной Думы Федерального Собрания Российской Федерации [Электронный ресурс]/Режим доступа: URL: https://sozd.duma.gov.ru/ свободный (дата обращения: 01.03.2026);
- Пономарева К. А. Применение Искусственных Нейронных Сетей При Решении Задач Прогнозирования // Наука Без Границ, № 1(41), 2020, С.44;
- Хавроненко М. В. Прогнозирование результатов рассмотрения законопроектов Государственной думой: модель нейронной сети // Политическая наука. — 2024. — № 3. — С. 211–240;
- Yano T., Smith N. A., Wilkerson J. Textual predictors of bill survival in congressional committees // Proceedings of NAACL HLT 2012. — P. 793–802.
- Micci-Barreca D. A preprocessing scheme for high-cardinality categorical attributes // ACM SIGKDD Explorations Newsletter. — 2001. — Vol. 3, № 1. — P. 27–32.
- Prokhorenkova L. et al. CatBoost: unbiased boosting with categorical features // Advances in Neural Information Processing Systems. — 2018. — Vol. 31. — P. 6638–6648.
- Sculley D. et al. Hidden technical debt in machine learning systems // Advances in Neural Information Processing Systems. — 2015. — Vol. 28. — P. 2503–2511.

