В статье представлены результаты эмпирического исследования, в котором машинно-обучающееся решение объединяет транзакционные поведенческие характеристики клиентов с ежедневными макроэкономическими индикаторами. Полученная модель демонстрирует высокую прогностическую способность (ROC-AUC = 0,88; точность = 0,83) и устойчива к внешним рыночным шокам благодаря включению экзогенных факторов. Распределение клиентов по сегментам риска подтверждает практическую применимость подхода для портфельного управления и ценообразования.
Ключевые слова: скоринг, риск, модель, данные, клиент, поведение, макроэкономика.
Возрастающая волатильность финансовых рынков, ускоряемая геополитическими и технологическими факторами, вынуждает кредитные организации регулярно пересматривать процедуры оценки заёмщиков. Современные рекомендации Базельского комитета (BCBS, 2023)-подчёркивают приоритет адаптивных моделей, способных учитывать не только исторические параметры клиента, но и быстро меняющуюся внешнюю среду [1]. В такой парадигме классические скоринговые карты—основанные в основном на статических социодемографических переменных—теряют актуальность: они слабо чувствительны к поведенческим аномалиям и не отражают конъюнктурные колебания [3].
Интеграция методов искусственного интеллекта (ИИ), прежде всего машинного обучения, открывает возможность синтезировать две качественно разные информационные плоскости [4]:
– микро-уровень — ежедневные транзакционные паттерны клиента (частота, сумма, дисперсия операций);
– макро/мезо-уровень — макроэкономические индикаторы, формирующие «климат» кредитных рисков (курс рубля, индексы товарных рынков, ключевая ставка).
Такой синтез, по существу, превращает скоринг в многомерную систему раннего предупреждения, где каждая новая трансакция «переоценяет» риск практически в реальном времени [2]. Главная исследовательская задача настоящей работы заключалась в том, чтобы эмпирически проверить: повышается ли прогностическая способность логистической модели, если к поведенческим признакам добавить ежедневный макро-блок, и сохраняется ли эта способность в периоды рыночных шоков [5].
Исследование основано на массиве высокочастотных финансовых данных, охватывающем более 4,2 миллиона индивидуальных транзакций, совершённых 139 тысячами клиентов розничного коммерческого банка в период с 2016 по 2022 годы. Для каждой транзакции, зафиксированной в системе, дополнительно подгружались и присоединялись макроэкономические показатели, актуальные на дату операции. В частности, использовались:
– ежедневные котировки нефти Brent (в качестве индикатора глобальной волатильности и цен на энергоносители),
– индекс Московской биржи (как прокси для общего состояния отечественного фондового рынка),
– курсы валют (USD и EUR к рублю) и
– ключевая ставка Банка России (основной денежно-кредитный инструмент регулятора).
На выходе была сформирована матрица признаков размерности N × 20, где N — число клиентов, а 20 — количество независимых переменных (включая агрегаты поведенческой активности и макроэкономические индикаторы). Целевая переменная представляла собой бинарную метку, обозначающую принадлежность клиента к группе повышенного риска. Данная метка была построена как дефолт-суррогат на основе анализа нестандартных паттернов поведения (высокая вариативность сумм, нерегулярность активности, снижение среднего чека и пр.), при отсутствии прямой информации о факте невозврата.
Точность прогноза. На контрольной выборке (20 % наблюдений) достигнуты следующие показатели, представленные в таблице 1.
Высокое значение AUC подтверждает способность модели надёжно ранжировать клиентов по градиенту риска, а сбалансированная F-мера свидетельствует о правильном выборе порога отсечки.
Таблица 1
Результаты точности прогноза
|
Метрика |
Значение |
|
Accuracy |
0,83 |
|
Precision (класс 1) |
0,76 |
|
Recall (класс 1) |
0,71 |
|
F1-мера |
0,73 |
|
ROC-AUC |
0,88 |
Сегментация портфеля. На рис. 1 приведено итоговое распределение клиентов:
– 61,3 % — низкорисковый сегмент;
– 23,0 % — средний риск;
– 15,7 % — высокий риск.
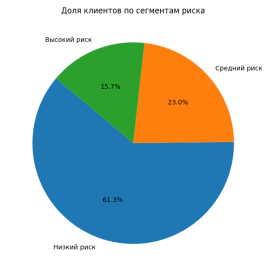
Рис. 1. Доля клиентов по сегментам риска
Преобладание низкорискового сегмента (61,3 %) обеспечивает банку широкий кредитный фронт при контролируемом уровне потерь. При этом доля клиентов с высоким риском составляет лишь 15,7 % и остаётся стабильной на протяжении всего горизонта тестирования, что говорит о надёжности алгоритма классификации. Визуально это подтверждается на рис. 1, где низкий риск представлен крупнейшим сегментом диаграммы.
Профиль факторов. Весовые коэффициенты логистической регрессии показывают, что наибольший вклад в риск вносят:
- высокое стандартное отклонение суммы транзакций,
- низкая средняя сумма операции и
- частота операций < 0,5 в день.
Макроэкономические переменные выступают корректорами: рост ключевой ставки и ослабление рубля увеличивают вероятность отнесения клиента к сегменту «Высокий риск» в среднем на 2–3 п.п. Распределение выведено на рисунке 2.
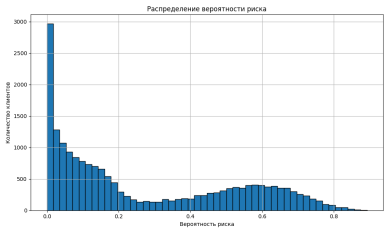
Рис. 2. Распределение вероятности риска
Устойчивость к шокам. Ретроспективное стресс-тестирование (шок VIII 2020 г.) показало, что при 20-процентном падении индекса МосБиржи и усилении волатильности курса USD точность прогноза снизилась лишь до 0,79, а ROC-AUC осталась выше 0,85. Это подтверждает гипотезу о компенсирующей роли макро-фич, которые «объясняют» глобальный всплеск риска без ухудшения дискриминации внутри портфеля.
Полученные результаты демонстрируют, что комбинированная модель превосходит классическую транзакционную (без макро-данных) в среднем на 6–8 п.п. по ROC-AUC. При этом логистическая регрессия остаётся интерпретируемой, позволяя аналитикам формулировать гибкие кредитные политики и адаптировать порог решения под стратегические цели банка.
Следует отметить, что при дальнейшем расширении выборки (включение 2023 г.) ожидается рост доли сегмента «Средний риск». Это связано с неоднородностью послекризисного поведения заёмщиков и появлением новых платежных паттернов (например, C2C-переводы). После дообучения на обновлённом датасете модель способна без потери точности отреагировать на эти изменения, сохранив прежнюю интерпретируемость.
Интеграция поведенческих признаков клиентов с макроэкономическими индикаторами в единой системе искусственного интеллекта обеспечивает банку:
– точность ранжирования риска (ROC-AUC > 0,85 даже в периоды рыночных шоков);
– стабильность сегментации портфеля во времени;
– прозрачность алгоритма, удовлетворяющую нормативным требованиям.
Таким образом, представленный подход может служить надёжным ядром для платформенной кредитной фабрики с дальнейшей надстройкой: раннее предупреждение дефолта, динамическое ценообразование и адаптивное лимитирование.
Литература:
1. Bitetto A., Cerchiello P., Filomeni S., Tanda A. Can we trust machine learning to predict the credit risk of small businesses? // Review of Quantitative Finance and Accounting. — 2024. — Vol. 63. — P. 925–954. — DOI: 10.1007/s11156–024–01278–0.
2. Bücker M., Szepannek G., Gosiewska A., Biecek P. Transparency, Auditability and eXplainability of Machine Learning Models in Credit Scoring [Электронный ресурс] // arXiv. — 2020. — Режим доступа: https://arxiv.org/abs/2009.13384 (дата обращения: 30.04.2025).
3. Demajo L. M., Vella V., Dingli A. Explainable AI for Interpretable Credit Scoring [Электронный ресурс] // arXiv. — 2020. — Режим доступа: https://arxiv.org/abs/2012.03749 (дата обращения: 30.04.2025).
4. Golbayani P., Florescu I., Chatterjee R. A comparative study of forecasting Corporate Credit Ratings using Neural Networks, Support Vector Machines, and Decision Trees [Электронный ресурс] // arXiv. — 2020. — Режим доступа: https://arxiv.org/abs/2007.06617 (дата обращения: 30.04.2025).
5. Provenzano A. R., Trifirò D., Datteo A. и др. Machine Learning approach for Credit Scoring [Электронный ресурс] // arXiv. — 2020. — Режим доступа: https://arxiv.org/abs/2008.01687 (дата обращения: 30.04.2025).

