Методы матричной факторизации для объектных рекомендаций
©2025 г. М. А. Жарова a,*
a ФИЦ ИУ РАН, Москва, Россия
* e-mail: zharova.ma@phystech.edu
Введение. Рекомендательные системы развиваются и решают всё более разнообразные задачи. Помимо персонализации — подбора релевантного контента пользователю — актуальна задача генерации взаимодополняющих объектов: нужно находить предметы, которые логично использовать вместе, а не просто соответствующие общим интересам пользователя [1].
Классические подходы (например, коллаборативная фильтрация) анализируют пользовательское поведение, предполагая, что схожие паттерны взаимодействий указывают на близость пользователей или объектов. Это хорошо работает для персонализации и поиска похожих предметов, но слабее — для комплементарных рекомендаций: объекты, используемые совместно, часто функционально различны и не демонстрируют явного сходства, а опора на глобальные пользовательские истории может ухудшать релевантность комплементарных предложений [2].
Один базовый подход — статистическое моделирование совстречаемости через ассоциативные правила, которое дает интерпретируемые паттерны совместного потребления. Однако такие методы требуют строгой фильтрации по частоте и надёжности правил, что уменьшает покрытие; ослабление фильтров ведет к росту нерелевантных рекомендаций. Поэтому статистика эффективна главным образом в высокочастотных сегментах [3].
Альтернатива — чисто контентные признаки (текст, категория, визуалка, метаданные). Теоретически они позволяют выявлять семантическую или функциональную совместимость, но на практике комплементарность контекстуальна и плохо формализуется: требуются экспертные разметки или сложная инженерия признаков/нейросети и большие датасеты. К тому же контент не всегда отражает реальное поведение — коллаборативные данные остаются наиболее надежным источником сигналов о совместном использовании [4].
Среди алгоритмов по работе с коллаборативными данными выделяют матричную факторизацию и нейросетевые подходы. Нейросети способны моделировать сложные зависимости, но требуют больших вычислений и данных. В качестве более интерпретируемой и вычислительно щадящей альтернативы целесообразно адаптировать методы факторизации к задаче комплементарных рекомендаций [5,6].
Классический путь — факторизация «пользователь–объект», что обучает модель на общей истории и требует постобработки (фильтрации похожих предметов или учета кратковременной совместности) для получения комплементарности. Это значит, что логика сопутствия задаётся вне процесса обучения [7].
Более прямой подход — факторизация матрицы «объект–объект», построенной по совместным действиям в ограниченном окне: здесь сигнал комплементарности заложен в данных, и модель непосредственно учится на соседстве объектов в сессиях. Это усиливает фокус на скрытых связях предметов, действительно используемых вместе. В работе предлагается сравнить оба подхода и оценить их применимость к задаче генерации взаимодополняющих рекомендаций.
2. Формализация подхода и постановка задачи. Формализация и постановка. Оба подхода — через матрицы user–item и item–item — сводятся к обучению матричной факторизации, где каждому объекту соответствует вектор скрытых признаков. Ключевое различие — способ формирования обучающих данных: он определяет характер эмбеддингов и логику поиска соседей. Ниже кратко изложены математические основы каждого подхода и предложены направления экспериментов: варианты построения обучающей выборки и настройка гиперпараметров модели.
2.1. Подход на основе user-item взаимодействий. Пусть дана разреженная матрица взаимодействий
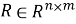
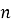
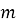
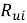
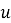
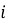
Модель матричной факторизации обучается на этой матрице с целью разложения:
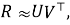
где
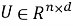
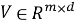
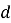
В классическом подходе прогноз интереса пользователя к объекту вычисляется как
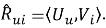
В данной работе эмбеддинги объектов
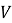
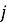
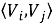
или косинусную близость между векторами
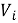
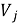
От схожести к комплементарности. Чтобы получать дополняющие, а не похожие объекты, нужно ввести ограничения при поиске ближайших эмбеддингов — иначе KNN вернёт аналоги (версии одного товара). Практичный способ — ограничить пространство кандидатов на уровне категорий: строить item-KNN по совстречаемости категорий, а затем внутри доверенных категорий искать ближайших объектов в латентном пространстве по косинусу. Для удаления слабых ассоциаций применяют квантильную фильтрацию: для каждой категории
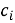
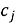
2.2. Подход на основе item-item взаимодействий. Альтернативный предлагаемый способ — обучение модели не на взаимодействиях пользователей, а на совместной встречаемости товаров. Формируется матрица
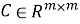
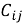
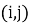
Итак, матрица
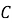
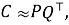
где
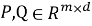
В отличие от симметричной матрицы схожести item-item, здесь пары
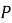
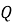
Рекомендации для объекта
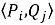
или косинусную близость между векторами
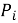
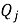
Как и в первом подходе, на этапе отбора кандидатов могут применяться дополнительные фильтры и ограничения для повышения релевантности выдач, например, по принадлежности к разным категориям или по правилам совместимости товаров.
Подход item–item даёт широкие возможности для экспериментов: менять окно взаимодействия (сессионное, временное, порядковое), правила фильтрации пар (по времени, категориям, числу взаимодействий) и архитектуру/гиперпараметры факторизационной модели. Поскольку обе матрицы после факторизации соотносятся с товарами, рекомендации можно строить либо по косинусной близости строк одной матрицы, либо между векторами из разных матриц (например, для каждого вектора из первой искать ближайшие во второй). Ограничения на уровни категорий остаются пригодными, но в этой работе мы используем единый заранее заданный набор фильтров и не исследуем их вариативность.
3. Проведение эксперимента. Перейдем непосредственно к проверке сформулированных гипотез на практике.
3.1. Эксперименты с моделями user–item. Протестирована группа моделей, обучающихся на матрице взаимодействий (user–item) и предсказывающих вероятность положительной реакции пользователя. Цели: выбрать подходящую модель по истории покупок, изучить влияние ограничений при генерации рекомендаций и весов взаимодействий, а также оценить пригодность подхода для комплементарных рекомендаций.
3.1.1. Выбор моделей и ограничения. В тесте использованы три популярных метода факторизации: ALS и BPR (из implicit [10]) и LightFM. Обучение проводилось на разрежённых данных о покупках. Модели implicit не имеют жёстких ограничений по объёму входа; реализация LightFM (версия Lyst [11]) ограничена по числу взаимодействий — около
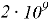
3.1.2. Сбор данных. В данных много редких пользователей и объектов; чтобы уменьшить шум и ускорить обучение, такие записи отсекались. Порог отсева подбирался индивидуально в каждом варианте: 5–10 взаимодействий за период.
3.1.3. Обучение и выбор архитектуры. Для отбора архитектуры все модели обучались на одинаковых трёхмесячных данных и со сравнимыми гиперпараметрами. Из-за большого числа объектов (≈13 млн) излишняя сложность гиперпараметров была нецелесообразна. Ограничения на комплементарные категории при поиске соседей на этом этапе не вводились. Результаты (табл. 1) показали преимущество LightFM; дальнейшие эксперименты выполнялись с ней.
Таблица 1. Сравнение качества моделей в подходе user-item
|
Метрика |
ALS |
BPR |
LightFM |
|
precision@1 |
0.00111 |
0.00173 |
0.00196 |
|
precision@3 |
0.00203 |
0.00285 |
0.00341 |
|
precision@7 |
0.00315 |
0.00415 |
0.00497 |
|
gini@1 |
0.87895 |
0.81874 |
0.80252 |
|
gini@3 |
0.91258 |
0.80667 |
0.80679 |
|
gini@7 |
0.93124 |
0.80273 |
0.79225 |
3.1.4. Ограничение области поиска и расширение датасета. Предыдущий эксперимент проводился на данных, собранных за 3 мес., что не являлось максимальным количеством, доступным для модели LightFM. Объем датасета был расширен до 7 мес., что значительно повлияло на метрики качества (табл. 2).
Таблица 2. Сравнение вариантов модели LightFM в подходе user-item
|
LightFM, 7 мес |
Добавлены ограничения |
Ограничения и BM25 | |
|
precision@1 |
0.00240 |
0.00264 |
0.00275 |
|
precision@3 |
0.00429 |
0.00467 |
0.00487 |
|
precision@7 |
0.00630 |
0.00711 |
0.00720 |
|
gini@1 |
0.82203 |
0.83539 |
0.83329 |
|
gini@3 |
0.83818 |
0.84970 |
0.84875 |
|
gini@7 |
0.84218 |
0.85427 |
0.85393 |
Фильтрация и ускорение поиска. Изначально поиск велся без ограничений, что давало много нерелевантных рекомендаций (в том числе из несопутствующих категорий). Введение фильтров на этапе генерации улучшило качество и дало небольшой прирост метрик. Для ускорения поиска ближайших соседей использовалась Faiss с векторными индексами [12,13].
3.1.5. Улучшение LightFM. В модель LightFM добавили веса взаимодействий (число покупок) и применили BM25-нормализацию с
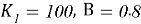
3.2. Эксперименты с моделью item-item. Основная архитектура — LightFM, использованная для сопоставления с user–item.
3.2.1. Сбор данных. Матрица item–item строится из совместных покупок в заданном временном окне: пара считается положительной, если товары куплены одним пользователем в периоде. Распределение пар смещено влево, поэтому применяется фильтрация по числу совместных покупок (от 4 до 30 в зависимости от покрытия). Это сократило число уникальных пар и ускорило обучение более чем в 20 раз относительно user–item.
3.2.2. Быстрое обучение позволило усложнить модель: увеличение размерности эмбеддингов и max_sampled улучшило качество, хотя потребовалось больше эпох (оптимально ≈200). Эффективнее всего искать соседей по правой матрице разложения; добавление BM25 также повышает метрики.
3.2.3. Формирование обучающего датасета и фильтры. Вариировали окно сопутствия — лучшее значение ≈10 дней: при увеличении окна число пар росло, но метрики падали (появлялся шум). На ранних этапах вводились жёсткие ограничения (совпадение пола/возраста, несовпадение категорий, ограничения по ценовым диапазонам), что давало интерпретируемые, но узкие рекомендации с низким покрытием. Постепенное ослабление ограничений улучшало метрики, повышая покрытие. В финале введена фильтрация пар по числу совместных покупок с минимальным порогом 15 — это отсекает слабые/случайные связи и снижает влияние редких товаров (см. табл. 3).
Таблица 3. Сравнение результатов по экспериментам в item-item
|
Метрика |
Эксперимент | |||
|
1 |
2 |
3 |
4 | |
|
precision@1 |
0.00157 |
0.00170 |
0.00201 |
0.00238 |
|
precision@3 |
0.00329 |
0.00356 |
0.00433 |
0.00466 |
|
precision@7 |
0.00553 |
0.00597 |
0.00720 |
0.00724 |
|
gini@1 |
0.77854 |
0.77281 |
0.81070 |
0.80344 |
|
gini@3 |
0.78389 |
0.77859 |
0.82508 |
0.79850 |
|
gini@7 |
0.78294 |
0.77837 |
0.83165 |
0.78419 |
|
Покрытие товаров |
3 млн |
3 млн |
6 млн |
15 млн |
Примечание. Пояснения по номерам экспериментов:
1 — без BM25 и без ограничений при поиске; при подготовке датасета применялись фильтры по цене, возрасту, полу и категории. 2 — как 1, но с добавленным BM25. 3 — относительно 2: введены ограничения при поиске; сняты все фильтры формирования датасета, кроме требования разной категории. 4 — относительно 3: сняты все фильтры при формировании датасета.
По итогам: LightFM в постановке item–item дала чуть большее покрытие, лучшую точность на дальних позициях и обучалась примерно в 2 раза быстрее при равных ресурсах. В A/B-тесте в блоке сопутствующих товаров рост выручки у item–item оказался более чем в 2 раза выше, чем у user–item. Это подтверждает гипотезу, что обучение на матрице item–item более пригодно для комплементарных рекомендаций.
Заключение. Рассмотрены два подхода к комплементарным рекомендациям на основе эмбеддингов: классическая факторизация user–item с поиском ближайших векторов и факторизация item–item матрицы совстречаемости, построенной по временным окнам взаимодействий.
Эксперименты показали: user–item даёт лучшее ранжирование на верхних позициях (выше метрики точности в начале выдачи), но требует больше ресурсов; item–item обеспечивает лучшие результаты с ~10-й позиции, повышает разнообразие рекомендаций и обучается значительно быстрее. Выбор зависит от целей и ограничений: при приоритете качества первых результатов и наличии ресурсов — user–item; для более лёгкой, масштабируемой и разнообразной системы — item–item.
СПИСОК ЛИТЕРАТУРЫ
- McAuley J., Pandey R., Leskovec J. Inferring Networks of Substitutable and Complementary Products // arXiv:1506.08839, 2015.
- Shi Y., Larson M., Hanjalic A. Attribute-Aware Recommender System Based on Collaborative Filtering: Survey and Classification // Frontiers in Big Data. 2020. V. 2. № 49.
- Deshpande M., Karypis G. Item-based top-N Recommendation Algorithms // ACM Transactions on Information Systems (TOIS). 2004. V. 22. № 1. P. 143–-177.
- Sinha L., Sinha N. Personalized Diversification of Complementary Recommendations with User Preference in Online Grocery // Frontiers in Big Data. 2023. V. 6.
- Rendle S., Krichene W., Zhang L., Anderson J. Neural Collaborative Filtering vs. Matrix Factorization Revisited // Proc. 14th ACM Conf. on Recommender Systems. Brazil, 2020. P. 240–248.
- Zharova M., Tsurkov V. Boosting Based Recommender System // J. Computer and Systems Sciences International. 2024. V. 63. P. 922–940.
- Zharova M., Tsurkov V. Neural Network Approaches for Recommender Systems // J. Computer and Systems Sciences International. 2024. V. 62. P. 1048–1062.
- Zhou Y., Wilkinson D., Schreiber R., Pan R. Large‑Scale Parallel Collaborative Filtering for the Netflix Prize // Proc. Intern. Conf. on Algorithmic Applications in Management (AAIM). Shanghai, China, 2008. P. 337–348.
- Chowdhury P. Evaluating the Effectiveness of Collaborative Filtering Similarity Measures: A Comprehensive Review // Procedia Computer Science. 2024. V. 235. P. 2641–2650.
- Имплементация ALS на Python // GitHub. Implicit: Webcite https://github.com/benfred/implicit (accessed: 10.07.2025).
- Имплементация библиотеки LightFM // GitHub. LightFM: webcite https://github.com/lyst/lightfm (accessed: 10.07.2025).
- Имплементация Faiss для Python // GitHub. Faiss-wheels: webcite https://github.com/kyamagu/faiss-wheels (accessed: 10.07.2025).
- Douze M., Guzhva A., Deng C. The Faiss Library // arXiv:2401.08281, 2025.
- Amati G. BM25 // In Encyclopedia of Database Systems. Boston, MA: Springer, 2009. P. 257–260.
1

