В статье рассматривается процесс дообучения модели автоматического распознавания речи Whisper-small на пользовательском датасете китайской речи, произносимой русскоязычными студентами. Проведён анализ теоретических основ ASR-систем, обоснован выбор модели, описаны этапы дообучения и оценка результатов. Представлены количественные метрики, демонстрирующие значительное повышение качества распознавания и снижение задержки при обработке аудио. Работа ориентирована на практическое применение в образовательных языковых чат-ботах .
Ключевые слова : автоматическое распознавание речи, китайский язык, Whisper, дообучение, Telegram-бот, Character Error Rate.
Введение
Изучение китайского языка — востребованная задача для студентов России. Одним из важных аспектов является развитие устной речи и правильного произношения. Традиционные методы не всегда обеспечивают быструю обратную связь, особенно при самостоятельном обучении.
Технологии автоматического распознавания речи (ASR) позволяют автоматизировать проверку произношения и интегрировать эту функцию в обучающие платформы, например, в чат-боты на базе ИИ в Telegram.
Однако стандартные ASR-модели, обученные на речи носителей, часто плохо справляются с речью изучающих язык из-за акцентов и ошибок. Для решения этой проблемы требуется дообучение — адаптация модели под специфические данные целевой аудитории.
В проекте была выбрана многоязычная модель Whisper от OpenAI и дообучена на аудиоданных русскоязычных студентов, изучающих китайский. Цель — создать систему, способную точно распознавать китайскую речь с учётом акцента и специфики произношения, и внедрить её в Telegram-бота для интерактивной языковой практики.
1. Модели ASR и их назначение
ASR — это технология преобразования устной речи в текст [1]. Она применяется в голосовых помощниках, автоматической транскрипции и обучении языкам.
Современные ASR-системы строятся на нейросетях, часто с архитектурой трансформеров, обеспечивающих высокую точность даже при шуме и вариативности говорящих [2]. Процесс включает извлечение аудиопризнаков, кодирование и языковую модель для вывода текста [3].
Проблема для образовательных задач — недостаточная адаптация под речь изучающих язык с акцентом и ограниченным словарём, особенно для тональных языков, таких как китайский [4]. ASR-системы помогают ускорить и автоматизировать обучение устной речи [5], но требуют дообучения для повышения точности.
2. Что такое дообучение модели
Дообучение (fine-tuning) — адаптация предобученной модели к новой, узкой задаче с помощью специализированных данных [6]. Whisper обучалась на больших корпусах с разными языками и условиями, но не покрывает все вариации речи изучающих язык [7].
Дообучение корректирует параметры модели с низкой скоростью обучения, чтобы избежать забывания прежних знаний [6]. В проекте модель адаптировалась к речи русскоязычных студентов с характерными ошибками и акцентом.
Эффективность подтверждена снижением ошибок CER и WER при адаптации к целевой аудитории.
3. Обоснование выбора модели Whisper
Whisper — открытая многоязычная ASR-модель от OpenAI, обученная на 680 000 часов аудиоданных [7]. Она поддерживает несколько размеров моделей: tiny, small, medium, large.
Для проекта выбрана версия whisper-small — компромисс между точностью и вычислительными ресурсами. Она подходит для обучения на одной GPU среднего класса и сохраняет высокую точность после дообучения [9]
Преимущества:
— Поддержка китайского языка и многоязычность.
— Устойчивость к акцентам и нерегулярной речи.
— Открытый код и интеграция с Hugging Face.
— Подходит для университетских и персональных систем.
4. Подготовка кастомного датасета
Данные собраны с практических занятий, участники — русскоязычные студенты с разным уровнем китайского. Каждый аудиофайл — отдельная фраза с прилагаемой транскрипцией.
Аудио стандартизировано:
— Частота дискретизации — 16 кГц;
— Моно;
— Длительность 1–10 секунд.
Данные разделены на обучающую и валидационную выборки (90/10), разделение рандомизировано по говорящим для предотвращения переобучения.
5. Процесс дообучения модели
Дообучение проходило на GPU NVIDIA RTX 3060, с использованием библиотек transformers, datasets, torch, evaluate и accelerate.
Параметры обучения:
— Learning rate — 1e-5;
— Эпох — 10;
— Batch size — 8;
— Gradient accumulation — 2;
— Mixed precision (fp16) включена.
Данные токенизировались встроенным токенизатором Whisper, обучение велось через класс Trainer с вычислением метрики CER [10].
Специфика китайского языка учитывалась в токенизации на базе SentencePiece без пробелов между словами и в особенностях тональной фонетики [11,12].
6. Метрики оценки и анализ результатов
Основная метрика — Character Error Rate (CER) — отражает ошибки на уровне символов, что важно для китайского письма, где слова состоят из иероглифов. Рассчитывается по формуле:
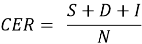
где:
— S — число замен,
— D — число удалений,
— I — число вставок,
— N — общее количество символов в эталонной транскрипции.
CER особенно актуален при распознавании китайской речи, поскольку китайский язык является морфослографическим — каждое слово обычно соответствует одному или двум иероглифам.
Второй показатель — Latency — среднее время обработки аудиофрагмента, важно для интерактивных приложений. Сопоставление метрик базовой и дообученной модели представлено в таблице 1.
Таблица 1
|
Модель |
Средний CER |
Средняя задержка (Latency) |
|
Whisper (базовая) |
30.02 % |
6.33 сек |
|
Дообученная модель |
5.96 % |
5.15 сек |
Дообучение модели на данных, соответствующих целевой задаче, привело к значительному улучшению качества распознавания — средний Character Error Rate снизился почти в 5 раз, с 30 % до 6 %. Это подтверждает, что Whisper обладает высокой способностью к адаптации и может быть эффективно перенастроена под специализированные типы речи.
Кроме того, наблюдалось уменьшение средней задержки распознавания на 1.2 секунды, что может быть связано с лучшей сходимостью модели и ускоренным декодированием в условиях предсказуемых входных данных.
Таким образом, дообученная модель значительно превосходит исходную в условиях, приближенных к реальному сценарию использования — взаимодействию Telegram-бота со студентами, изучающими китайский язык.
7. Заключение
Реализовано дообучение модели Whisper-small на специализированном датасете китайской речи русскоязычных студентов. Проведена подготовка данных и настройка обучения. Эксперимент показал существенное улучшение распознавания и снижение задержек.
Подход эффективен даже при ограниченных ресурсах и открывает перспективы для адаптированных речевых систем в образовании и межъязыковом взаимодействии.
Литература:
- Wolf T., Debut L., Sanh V., Chaumond J., Delangue C., Moi A. и др. Transformers: State-of-the-Art Natural Language Processing // Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. — 2020. — С. 38–45.
- Vaswani A. et al. Attention is all you need // Advances in Neural Information Processing Systems, 2017. — Vol. 30.
- Hinton G. et al. Deep Neural Networks for Acoustic Modeling in Speech Recognition // IEEE Signal Processing Magazine. — 2012. — Vol. 29(6). — P. 82–97.
- Zhao Y., Li X., Fung P. Improving accented speech recognition with multi-task learning // Interspeech 2018: Proceedings. — 2018. — С. 2444–2448.
- Wang Y., He Y., Deng L. Learning Speech Recognition from Speech Translation // Proceedings of ICASSP 2020. — 2020. — С. 7364–7368.
- Журавлёв А. И., Лаптев Д. С. Искусственный интеллект: модели, обучение и приложения. — М.: Наука, 2021. — 432 с.
- Ruder S. Transfer Learning — Machine Learning’s Next Frontier. — 2019. URL: https://ruder.io/transfer-learning/ (дата обращения: 25.05.2025).
- Radford A., Gao J., Xu T. и др. Robust Speech Recognition via Large-Scale Weak Supervision. — OpenAI, 2022. — URL: https://openai.com/research/whisper (дата обращения: 25.05.2025).
- Zhang Y., Chan W., Jaitly N. Very Deep Convolutional Networks for End-to-End Speech Recognition // ICASSP 2017: Proceedings. — 2017. — С. 4845–4849.
- Liu P., Zhang W., Fu Y. и др. SentencePiece Tokenizer for Multilingual Text-to-Speech // ICASSP 2022: Proceedings. — 2022. — С. 7967–7971.
- Кононов А. П. Основы фонетики китайского языка. — СПб.: СПбГУ, 2019. — 214 с.
- Ханевская С. И., Чжао Л. Методические особенности формирования произносительных навыков при обучении китайскому языку русскоязычных студентов // Вестник МГЛУ. — 2020. — № 12 (837). — С. 128–137.

