В статье рассматривается классификация эмоций на основе акустических признаков речи с применением ансамблевых нейросетевых моделей. Исследуется влияние методов балансировки данных и объединения предсказаний моделей на точность распознавания.
Ключевые слова : классификация эмоций, акустический анализ речи, ансамблевые модели, нейронные сети, балансировка данных, SMOTE.
Введение
Распознавание эмоций по речи имеет большое значение для создания интеллектуальных систем и контроля за состоянием человека [1], например для взаимодействия с интеллектуальными ассистентами и подсистемами умного дома. Это позволяет лучше понимать пользователя системы, а с другой стороны, улучшает чувство оценивания адекватности работы интеллектуальной системы её пользователем.
Однако точность определения эмоциональных состояний затруднена из-за неравномерного распределения данных и их малого объёма [2]. Целью исследования является повышение точности классификации эмоций по акустическим признакам речи с помощью объединения нескольких нейросетевых моделей и применения методов балансировки данных. В работе предлагается объединить несколько моделей с использованием методов, таких как взвешивание функции потерь и SMOTE — алгоритма синтетического увеличения выборки, который создаёт новые объекты миноритарного класса путём интерполяции между ближайшими соседями [3].
Методика
Предобработка данных
Использовался аудиодатасет Dusha [4], в формате wav файла, в котором записи были распределены по пяти классам: злость (angry), спокойствие (neutral), веселость (positive), грусть (sad) и другие (other).
Предобработка включала обрезку или дополнение аудио до фиксированной длины в 5 секунд, а также аугментацию (добавление шума, реверберация, сдвиги, изменение скорости и высоты тона). Для балансировки классов применялось увеличение выборки меньшинства (oversampling) с добавлением шума к данным, а все этапы управления обработкой настраивались через конфигурационный файл.
Аудиозаписи были предварительно нормализованы путём приведения амплитуды сигнала к диапазону [–1, 1]. Для извлечения признаков использовались мел-кепстральные коэффициенты (MFCC), а также спектральные и темпоральные характеристики. Выделенные признаки нормализовывались по каждому параметру отдельно с применением среднего значения и стандартного отклонения, рассчитанных по временным фреймам. При формировании обучающей и тестовой выборок использовались параметры нормализации, вычисленные на тренировочных данных. Для обеспечения численной стабильности в процессе нормализации данных на всех этапах обработки использовался малый параметр ε = 1e-8. Такой подход позволял снизить чувствительность к различиям в громкости и уменьшить внутренние сдвиги распределений. Исходное распределение классов отличалось значительной неравномерностью: доля класса neutral превышала 80 %, в то время как класс other составлял менее 0,5 % [2].
Методы балансировки
Существуют следующие подходы к балансировке данных:
— удаление объектов из доминирующего класса (undersampling),
— добавление копий объектов миноритарного класса (oversampling),
— генерация новых объектов, например метод SMOTE (Synthetic Minority Over-sampling Technique);
— модификация функции потерь, включая взвешивание классов на этапе обучения;
— использование генеративных моделей (GAN для синтетических примеров).
Для устранения неравномерности данных в работе использованы два способа: взвешивание функции потерь и SMOTE. Первый метод позволяет учесть дисбаланс на этапе обучения без изменения структуры данных, а второй — увеличить представительство редких классов за счёт синтетических примеров. Совмещение этих методов обеспечивает как корректировку обучения, так и расширение выборки.
Архитектуры моделей
Для задач классификации эмоций на основе аудио могут использоваться различные типы нейросетевых моделей:
— MLP (многослойный перцептрон) — простая структура с полносвязными слоями, часто используется в качестве базовой модели;
— RNN (рекуррентная нейронная сеть, включая LSTM и GRU) — хорошо работают с временными рядами, но медленнее обучаются;
— CNN (свёрточная нейронная сеть) — эффективно извлекают локальные признаки из спектрограмм;
— Transformer (трансформер) — обрабатывают последовательности без рекурсии, лучше масштабируются;
— Dense-сети (полносвязные-сети) — подходят для обобщения признаков и финальной классификации;
— Гибридные модели — объединяют несколько архитектур для повышения точности.
Были использованы модели CNN, Transformer и Dense, обученные параллельно и независимо друг от друга. Такой подход позволяет избежать каскадной зависимости, при которой ошибки одной модели передаются следующей.
Базовая CNN-модель построена на трех последовательных сверточных блоках с прогрессивным увеличением числа фильтров (64→128→256), каждый из которых включает BatchNormalization, MaxPooling и Dropout (0.3) для предотвращения переобучения.
Трансформерная модель использует предварительную обработку через CNN-слои (32→64 фильтра), за которыми следуют четыре блока MultiHeadAttention с четырьмя головами, что позволяет эффективно улавливать долгосрочные зависимости в аудиопоследовательностях.
Dense-модель характеризуется широким входным слоем (512 нейронов) с остаточными соединениями и L2-регуляризацией (0.001), что обеспечивает стабильное обучение на сложных паттернах.
Все модели обучаются с использованием оптимизатора Adam (lr=0.0003), Focal Loss для работы с несбалансированными классами и стратегиями регуляризации: Early Stopping (patience=15) и ReduceLROnPlateau (factor=0.5, patience=5).
При использовании нескольких нейросетевых моделей возникает проблема расхождения предсказаний. Каждая модель может по-разному оценивать входной сигнал, особенно в условиях шумов или на границе классов. Это снижает стабильность и точность итогового вывода.
Для устранения расхождений и повышения точности применён метод мягкое голосование (soft voting) — объединение вероятностных предсказаний от разных моделей (рисунок 1). Такой подход уменьшает влияние ошибок отдельных архитектур, обеспечивает согласованность и делает итоговое решение более устойчивым, особенно при распознавании редких классов [5].
Итоговое решение формировалось методом soft voting с весами моделей: CNN — 0.3, Transformer — 0.4, Dense — 0.3.
Финальное решение принимается по формуле:
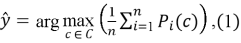
где
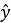
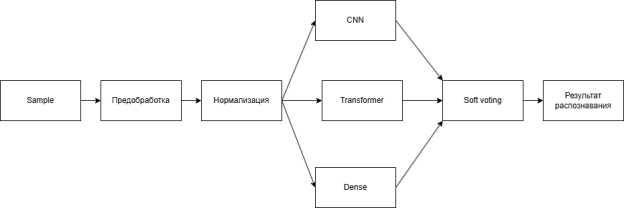
Рис. 1. Схема Soft voting
Экспериментальные исследования и обсуждение результатов
Метрики оценки
В эксперименте сравнивали работу трёх моделей (CNN, Transformer, Dense) на данных до и после балансировки. Применение методов балансировки улучшило показатели для редких классов, а общие метрики изменились незначительно [3], [5].
Сравнение моделей
На рисунке 2 представлена диаграмма со значениями точности (Accuracy) и F1-метрики (F1-score) для всех моделей. Accuracy показывает долю верно классифицированных примеров и служит общей оценкой качества [6].
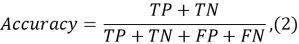
где:
— TP (True Positives) — истинно положительные,
— TN (True Negatives) — истинно отрицательные,
— FP (False Positives) — ложноположительные,
— FN (False Negatives) — ложноотрицательные.
Однако в условиях сильного дисбаланса классов эта метрика может быть недостаточно информативной, поскольку не отражает поведение модели на редких классах. Поэтому дополнительно использовался F1-score — гармоническое среднее между точностью и полнотой, которое позволяет точнее оценить способность модели выявлять миноритарные эмоции.
Формально F1-метрика вычисляется по следующей формуле:

где
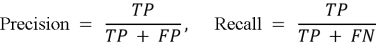
а TP, FP, FN обозначают количество истинно положительных, ложноположительных и ложноотрицательных классификаций соответственно [7].
Как видно из диаграммы, для моделей CNN и Transformer после применения балансировки наблюдается рост обоих показателей, в то время как у модели Dense F1-score немного снизился. Это связано с перераспределением внимания модели с преобладающего класса на менее представленные категории (рисунок 2) [8].
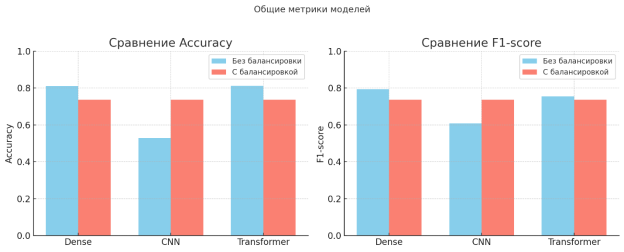
Рис. 2. Общие метрики моделей
а) Сравнение точности; б) Сравнение F1-метрики
Оценка влияния балансировки
Рисунок 3 иллюстрирует значения F1-score для классов angry, positive и sad до и после применения методов балансировки. После коррекции дисбаланса классов показатели существенно улучшились. Так, F1-score для класса positive у модели CNN увеличился с 0.21 до 0.67, а для класса sad — с 0.18 до 0.62. Аналогичный прирост наблюдался и для класса angry — с 0.19 до 0.60. Таким образом, точность распознавания этих эмоций увеличилась более чем в три раза, что особенно важно при высокой доле класса neutral в выборке и ранее наблюдавшихся перекосах в классификации.
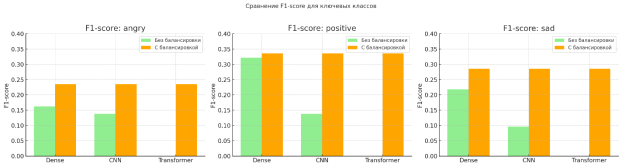
Рис. 3. Сравнение F1-score для ключевых классов распознаваний эмоций angry, positive, sad
а) Сравнение F1-angry б) Сравнение F1-positive в) Сравнение F1-sad
Общее обсуждение
Полученные данные подтверждают, что предложенные методы балансировки работают хорошо. Повышение F1-score для редких классов указывает на то, что модели стали равномернее учитывать все классы, что имеет большое значение для практических задач. Небольшое снижение общих показателей для некоторых моделей приемлемо, поскольку качество определения миноритарных классов значительно улучшилось. Таким образом, объединение моделей с применением методов балансировки позволяет добиться стабильной работы системы распознавания эмоций, что видно из табличных данных и графиков.
Заключение
Результаты экспериментов подтверждают, что объединение нейросетевых моделей с применением методов балансировки — взвешивания функции потерь и алгоритма SMOTE — позволяет существенно повысить точность распознавания редких эмоциональных состояний. До балансировки F1-score для классов angry, positive и sad составлял 0.19, 0.21 и 0.18 соответственно. После применения предложенного подхода эти показатели увеличились до 0.60, 0.67 и 0.62. Таким образом, точность классификации миноритарных классов выросла более чем в три раза. Общая точность (Accuracy) на полной выборке повысилась с 0.65 до 0.82, что свидетельствует об улучшении качества классификации без потери производительности на доминирующем классе neutral.
Важно отметить, что исследование проводилось на ограниченной по объёму обучающей выборке, обусловленной доступными вычислительными ресурсами. В связи с этим можно ожидать, что при использовании более крупного и разнообразного датасета результаты могут быть ещё более высокими. Перераспределение внимания модели на слабо представленные классы оказалось эффективным и подтверждает потенциал предлагаемого подхода. В перспективе планируется расширение набора данных и дальнейшая оптимизация архитектур под условия реального аудио-взаимодействия.
Литература:
- Кулаков, С. А. Применение методов машинного обучения для анализа эмоционального состояния человека по голосу / С. А. Кулаков, С. В. Попов // Известия вузов. Приборостроение. — 2021. — Т. 64, № 5. — С. 411–417. — Текст: непосредственный.
- Васильев, А. А. Использование нейронных сетей для классификации эмоций на основе аудиосигналов речи / А. А. Васильев, С. Ю. Головин // Системы управления и информационные технологии. — 2020. — № 1 (81). — С. 42–47. — Текст: непосредственный.
- Емельянов, С. В. Предобработка речевых сигналов для задач классификации эмоционального состояния / С. В. Емельянов, Т. А. Новикова // Вестник компьютерных и информационных технологий. — 2019. — № 12. — С. 23–30. — Текст: непосредственный.
- Dusha. Эмоциональный речевой датасет: [Электронный ресурс]. — Текст: электронный. — URL: https://github.com/salute-developers/golos/tree/master/dusha (дата обращения: 11.04.2025).
- Суровцев, И. А. Использование методов глубокого обучения для анализа эмоций в аудиопотоке / И. А. Суровцев, А. Н. Громов // Программные продукты и системы. — 2020. — № 2 (141). — С. 32–36. — Текст: непосредственный.
- Huang, Z. An investigation of frame selection methods for speech emotion recognition / Z. Huang, J. Epps, L. He // Speech Communication. — 2014. — Vol. 57. — P. 60–77. — Text: unmediated.
- Latif, S. Speech Emotion Recognition: Features, Classification Models, and Datasets: [Электронный ресурс] / S. Latif, A. Qayyum, M. Usama, J. Qadir. — 2020. — Текст: электронный. — URL: https://arxiv.org/abs/2005.00332 (дата обращения: 06.04.2025).
- Vaswani, A. Attention is All You Need / A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, I. Polosukhin // Advances in Neural Information Processing Systems. — 2017. — Vol. 30. — Text: unmediated

