Эффективность работы любого современного программного комплекса во многом зависит от того, насколько качественно организовано его взаимодействие с базами данных. Запросы на языке SQL составляют неотъемлемую и существенную часть общего исходного кода проекта: они напрямую влияют на скорость отклика интерфейса, стабильность серверной части и общую архитектурную чистоту системы. По этой причине к написанию SQL-кода применим тот же строгий инженерный подход, что и к оценке качества традиционного программного обеспечения.
Систематизировать этот процесс позволяет актуальный стандарт ГОСТ Р ИСО/МЭК 25010–2015 [1], устанавливающий единые правила для анализа программных продуктов. Полная структура нормативной модели со всеми базовыми характеристиками представлена на рисунке 1.
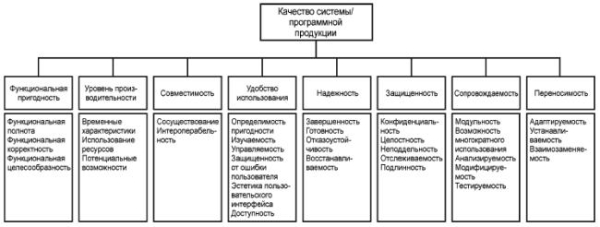
Рис. 1. Модель качества программной продукции
Модель ориентирована на крупные программные системы, из-за чего её невозможно переложить на синтаксис отдельных поисковых запросов в чистом виде. Потому необходимо исключить несколько характеристик, показатели которых для декларативного кода остаются неизменными или зависят от внешней инфраструктуры:
- Функциональная пригодность. Поскольку запросы изначально составляются разработчиком вручную под конкретные бизнес-требования, это обеспечивает стопроцентное выполнение функциональных задач.
- Совместимость. Отдельный поисковый запрос функционирует изолированно в рамках конкретной пользовательской сессии СУБД, не вступает во взаимодействие с другими приложениями и не может нарушить их автономную работу.
- Надёжность. Оператор SELECT выполняет исключительно чтение данных. Конструкции с ним детерминированы и сами по себе не способны повлиять на отказоустойчивость или скорость восстановления СУБД после сбоев.
- Защищённость. В рамках данной работы рассматриваются статические конструкции, где отсутствуют механизмы динамической склейки строк. Вопросы разграничения прав доступа к таблицам и предотвращения инъекций решаются на уровне глобальной архитектуры базы данных, а не внутри самого текста запроса.
Таким образом, для детального изучения синтаксиса остаются четыре ключевые характеристики, которые сильнее всего подвержены влиянию выбранного стиля написания кода и которые представлены в таблице 1.
Таблица 1
Адаптированная модель характеристик качества SQL-запросов
|
Характеристика |
Критерий |
Описание применения критерия |
|
Уровень производительности |
Вычислительная стоимость (cost) [2] |
Расчетная величина, отражающая суммарные затраты ресурсов процессора и операций ввода-вывода при выполнении плана запроса |
|
Объём обрабатываемых данных (bytes) |
Количество информации в байтах, выделяемое оптимизатором СУБД в оперативной памяти для обработки алгоритма. Высчитывается, как и cost, в плане выполнения запроса [3] | |
|
Удобство использования |
Когнитивная сложность кода |
Количество уникальных логических операторов, соединений, группировок и условий |
|
Удобство сопровождения |
Глубина вложенности |
Максимальное количество уровней внутренних подзапросов, встроенных друг в друга |
|
Модульность конструкции |
Степень разделения сложной задачи на независимые шаги | |
|
Переносимость |
Соответствие стандарту ISO/IEC 9075 (ANSI SQL) [4] |
Процентная доля использования универсальных синтаксических конструкций по отношению к общему числу операторов и функций |
Для обеспечения объективности оценки по критериям модульность и переносимость будем использовать коэффициенты:
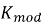
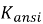
Формула коэффициента модульности, в котором под блоком понимается любое использование оператора SELECT:
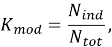
где
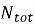
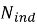
К независимым относятся те части запроса, которые могут быть выполнены СУБД изолированно, без обращения к переменным из внешнего контекста: например, обобщенные табличные выражения, некоррелированные подзапросы. Коррелированные подзапросы, встроенные в секции SELECT или WHERE и зависящие от внешнего цикла, снижают данный коэффициент. Чем ближе значение
Международный стандарт ISO/IEC 9075, в профессиональной среде исторически закрепившийся как ANSI SQL, устанавливает универсальный синтаксис, поддерживаемый большинством реляционных баз данных: стандартные соединения JOIN, оконные функции, операторы CASE. Проприетарные конструкции, такие как локальные функции обработки дат и пустых значений (NVL, SYSDATE в Oracle), делают код непереносимым на другие платформы (PostgreSQL или MS SQL).
Вычисление процента соответствия стандарту производится следующим образом:
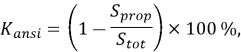
где
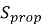
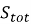
Стопроцентный результат означает идеальную переносимость, тогда как любое снижение показателя указывает на потенциальные финансовые и временные затраты при переносе программного проекта на другую архитектуру.
Оценку влияния синтаксиса на характеристики качества программного кода проводится на базе данных «Автовокзал» на платформе Oracle APEX, которая используется в дистанционном практикуме ВоГУ. Её модель, представленная на рисунке 2, включает в себя расценки за километр пути (km_prices), модели автобусов (models), автобусы (buses), населённые пункты (points), маршруты (routes) и рейсы (trips).
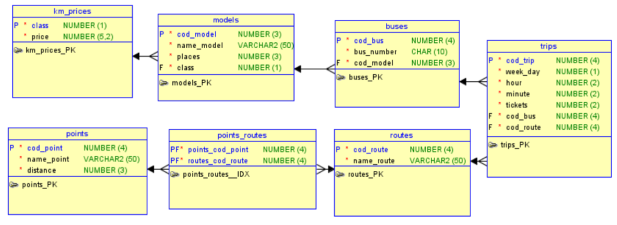
Рис. 2. Реляционная модель учебной базы данных «Автовокзал»
В ней объем информации превышает 5000 записей, что обеспечивает объективность тестирования: на заполненных таблицах оптимизатор СУБД тратит реальные вычислительные ресурсы, поэтому разница в производительности между оптимизированным и неэффективным кодом становится чёткой и измеримой.
Чтобы в полной мере раскрыть потенциал различных подходов к написанию запросов, необходимо составить достаточно сложную практическую задачу, которая будет включать в себя группировки, математические вычисления и многоуровневую фильтрацию. В результате было сформировано следующее условие:
«Определить рейтинг прибыльности моделей автобусов по выходным дням (суббота и воскресенье). Прибыль рейса вычисляется как: количество проданных билетов × максимальная протяженность маршрута × цена за километр для класса данной модели. Вывести название модели, суммарную прибыль, средний процент заполняемости автобусов этой модели и присвоить ранг, где 1 — самая прибыльная. Исключить из отчета модели, у которых средняя заполняемость менее 50 %».
Для получения итогового отчета необходимо объединить все шесть таблиц, предварительно рассчитать промежуточные показатели и выстроить финальный рейтинг. Два способа реализации представлены на рисунке 3: с левой стороны изображен классический вариант выборки, а с правой — код, оптимизированный согласно актуальным стандартам языка.

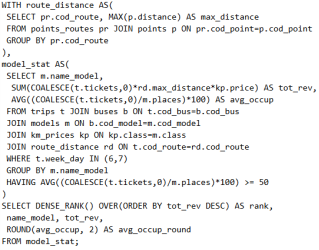
Рис. 3. Текст запросов
В классическом используется коррелированный подзапрос в секции вычислений, из-за чего сервер заново определяет максимальную дистанцию маршрута для каждой отдельной строки, удовлетворяющей условиям фильтрации. Возникающее при этом многократное сканирование связанных таблиц негативно сказывается на общей скорости выдачи результата.
Применение обобщенных табличных выражений, напротив, позволяет сформировать промежуточные показатели лишь один раз. Найденные дистанции сохраняются в оперативной памяти и в дальнейшем просто присоединяются к основному набору данных, что полностью исключает избыточную нагрузку на дисковую подсистему и процессор. Кроме того, последовательное разделение сложной задачи на изолированные шаги значительно упрощает визуальное восприятие алгоритма, снижая вероятность ошибок при его дальнейшей модернизации.
Итоговые результаты количественной оценки по адаптированным критериям качества продемонстрированы в таблице 2.
Таблица 2
Сравнительный анализ выполнения запросов
|
Характеристика |
Критерий |
Классический |
Современный |
|
Уровень производительности |
Вычислительная стоимость |
84 |
26 |
|
Объём обрабатываемых данных |
1 280 |
613 | |
|
Удобство использования |
Когнитивная сложность кода |
8 |
9 |
|
Удобство сопровождения |
Глубина вложенности |
3 |
1 |
|
Модульность конструкции |
|
| |
|
Переносимость |
Соответствие ISO/IEC 9075 (ANSI SQL) |
|
|
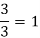
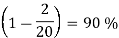
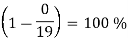
Оптимизированный в соответствии со стандартами запрос демонстрирует кратный прирост производительности: его вычислительная стоимость и объем потребляемой оперативной памяти существенно ниже показателей прямого метода. Современный синтаксис также выигрывает и по эксплуатационным характеристикам: благодаря плоской иерархии и высокому коэффициенту модульности такой код требует меньших когнитивных усилий для визуального восприятия и отладки. Вдобавок абсолютное соблюдение спецификаций ANSI SQL гарантирует надежную переносимость логики на любые реляционные СУБД.
В итоге можно сделать вывод, что оценка декларативного кода на основе ГОСТа Р ИСО/МЭК 25010–2015 выступает действенным инструментом повышения качества взаимодействия с базами данных. Эффективность выборки информации закладывается на уровне базовых синтаксических конструкций, что диктует необходимость тщательного продумывания архитектуры запросов до этапа их написания. Отказ от интуитивного наслаивания вложенных фильтров в пользу осознанного проектирования независимых структурных блоков решает сразу две ключевые задачи. Во-первых, обеспечивается высокая скорость выполнения операций за счет рационального распределения ресурсов оптимизатора. Во-вторых, формируется прозрачная, легко читаемая логика, кардинально снижающая временные затраты на дальнейшее сопровождение и модернизацию SQL-запросов.
Литература:
- ГОСТ Р ИСО/МЭК 25010–2015 Требования и оценка качества систем и программного обеспечения (SQuaRE). Модели качества систем и программных продуктов. Дата введения: 29.05.2015 — Текст: электронный // Меганорм: [сайт]. — URL: https://meganorm.ru/Data/600/60038.pdf (дата обращения: 14.05.2026).
- Oracle SQL Cost Calculation — With Formulas. — Текст: электронный // inLinkedin: [сайт]. — URL: https://www.linkedin.com/pulse/oracle-sql-cost-calculation-formulas-rajkumar-pathak-0fzwf#:~:text=When %20full %20system %20statistics %20are,Network %20Bytes %20 %C3 %97 %20Net %20Cost) (дата обращения: 19.05.2026).
- SQL Tuning Guide: Explaining and Displaying Execution Plans. — Текст: электронный // Oracle: [сайт] — URL: https://docs.oracle.com/en/database/oracle/oracle-database/19/tgsql/generating-and-displaying-execution-plans.html#GUID-E4ED3145–8ABD-4F40-B044–9AEFBD89409C (дата обращения: 18.05.2026).
- ISO/IEC 9075–2:2023. Information technology — Database languages — SQL — Part 2: Foundation (SQL/Foundation). — Geneva: International Organization for Standardization, 2023. — 1715 p. — Текст: непосредственный.

