В статье автор рассматривает различные способы передачи и распознавания текстовых данных при помощи фреймворка Qt на базе языка С++.
Ключевые слова: Qt, распознавание текста, QFile.
В ходе работы с текстом разработчики постоянно ищут компромисс между точностью обработки данных, скоростью и объемом используемой памяти. Особенно остро данная проблема встает при разработке программного обеспечения для работы с большими объемами текста, в связи с чем встает вопрос о том, как организовать программу таким образом, чтобы сохранялся этот баланс.
На сегодняшний день многие разработчики продолжают использовать программные пакеты на основе языка С++, лидирующее место среди которых занимает Qt Creator, позволяющий работать как с обширным встроенным инструментарием, так и со сторонними библиотеками, разработанными как для конкретного фреймворка, так и для базового языка C++. Для наибольшей прозрачности в рамках данной статьи будут использоваться основные методы из базового инструментария Qt.
При открытии файлов с исходными данными в большинстве случаев разработчики используют встроенный в Qt модуль QFile. Данный модуль представляет собой мощную надстройку над стандартными библиотеками C++, такими как iostream.h, ifstream.h и ofstream.h. Он обеспечивает удобный и высокоуровневый интерфейс для работы с файловой системой, что значительно упрощает разработку и снижает вероятность ошибок. Основные особенности QFile:
— универсальность заключается в том, что инструмент может работать с различными типами данных: текстами, двоичными файлами, изображениями и другими распространенными форматами;
— интеграция с другими частями. Qt имеет удобный механизм реализации для разработчика: например, для передачи структурированных данных можно использовать QDataStream, а для доступа к байтовым данным — QIODevice, подходящий инструмент определяется задачами;
— благодаря инструменту интеграции можно объединять действия разных модулей в одну цепочку и выполнять сложные операции без необходимости писать дополнительную логику;
— высокая скорость работы сохраняется даже при больших объемах информации, что важно в ситуациях, когда система обрабатывает множество данных одновременно [1, с. 148].
Таким образом полученный механизм отображен ниже:
file.open(QIODevice::ReadOnly);
source = file.readAll();
В ходе проверки такого способа на предмет отказоустойчивости была выявлена критическая проблема, связанная с использованием метода QFile::readAll() для обработки данных. Данный подход не способен возвращать корректный результат при работе с файлами, имеющими нестандартные или редко используемые кодировки. В результате, вместо ожидаемого содержимого файла, система выводила одно число — 0 или 2, в зависимости от типа кодировки. Это происходило из-за того, что модуль QFile интерпретировал данные как байтовый массив, не учитывая особенности текстовых кодировок, что приводило к некорректной обработке информации. В поисках возможных решений этой проблемы было принято решение переработать систему и внедрить модуль QTextStream, который является частью библиотеки Qt и унаследован от аналогичных текстовых потоков в стандартной библиотеке C++. В отличие от QFile, который работает с данными на уровне байтов, QTextStream интерпретирует файлы как текстовые данные, что позволяет ему автоматически обрабатывать различные кодировки. Это достигается за счет внутренних механизмов преобразования, которые анализируют структуру файла и корректно декодируют его содержимое [2, с. 43]. После дополнительных испытаний были получены три варианта программы и результаты на основе 10 файлов с разными размерами и кодировкой (таблица 1).
Таблица 1
Результаты испытаний различных подходов к обработке файлов
|
Тип обработки |
Время обработки |
Число корректно обработанных файлов |
|
QFile |
3 сек |
3/10 |
|
QTextStream |
24 сек |
10/10 |
|
QFile + QTextStream |
11 сек |
10/10 |
Исходя из полученных результатов можно сделать очевидный вывод о предпочтительном способе обработки: гибрид модулей QFile и QTextStream. В таком случае система чтение материалов из файла будет выглядеть следующим образом:
file.open(QIODevice::ReadOnly);
source = file.readAll();
if (source.length() < 100) // подразумевается что исходный документ имеет длину более 100 символов, требует настройки в зависимости от конкретных данных
{
file.close(); //сброс текстового курсора
file.open(QIODevice::ReadOnly);
QTextStream ts(&file);
ts.setCodec(«UTF-16"); //стандартный кодек для QPlainTextEdit — инструмента для открытия текстовых данных
source = ""; //”обнуление” строки
while (!ts.atEnd())
{
source.append((ts.readLine() + "\n»));
}
}
file.close();
В общем виде представить получившийся механизм открытия можно следующей блок-схемой (рис. 1).
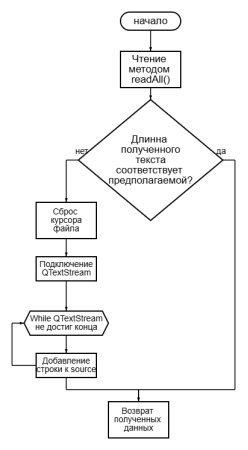
Рис. 1. Блок-схема полученного алгоритма чтения файлов
Таким образом, полученный механизм позволяет не только получать корректные данные из любых исходных файлов, не ограниченных одной кодировкой, но и производить все необходимые манипуляции с высоким уровнем скорости обработки и без избыточных затрат по оперативной памяти компьютера. Использование подобных гибридных методов в разработках позволит значительно повысить отказоустойчивость программ для работы с текстовыми данными, сохраняя при этом высокий уровень оптимизации.
Литература:
- Городничев, М. Г. Разработка кроссплатформенного программного обеспечения: Учебное пособие по направлениям подготовки бакалавров 09.03.01 Информатика и вычислительная техника, 02.03.02 Фундаментальная информатика и информационные технологии / М. Г. Городничев, Т. Д. Фатхулин, Х. А. Джабраилов. — Текст: непосредственный // Наукоемкие технологии. — 2023. — №. — С. 148.
- Мерзлякова, Е. Ю. Разработка прикладных программ в Qt Creator на С++: учебно-методическое пособие / Е. Ю. Мерзлякова. — Текст: непосредственный // Сибирский государственный университет телекоммуникаций и информатики. — 2023. — №. — С. 43.

