Статья посвящена исследованию методов анализа больших объемов текстовой информации с целью выявления смысловых паттернов. Рассматриваются современные подходы в области обработки естественного языка (NLP), включая тематическое моделирование, векторное представление слов, а также алгоритмы извлечения ключевых фраз и понятий. Обоснована актуальность применения данных методов в задачах поддержки принятия решений.
Ключевые слова: большие текстовые данные, смысловые паттерны, тематическое моделирование, обработка естественного языка, семантический анализ.
Современное общество ежедневно генерирует огромные объёмы неструктурированной текстовой информации: в социальных сетях, в электронных СМИ, в служебной документации, в отзывах пользователей и т. д. Эффективная обработка таких данных требует использования методов анализа текстов, способных не только обрабатывать большие массивы информации, но и извлекать из неё релевантные смысловые структуры — смысловые паттерны, которые могут лечь в основу управленческих и аналитических решений.
Смысловые паттерны представляют собой устойчивые семантические структуры, извлекаемые из текстов на основе анализа частотных, тематических и контекстуальных признаков. Современные методы анализа текстов опираются как на классические статистические подходы, так и на технологии искусственного интеллекта, включая машинное обучение и нейросетевые языковые модели.
Одним из ключевых этапов является предобработка текста. В научной литературе широко используются методы лемматизации, удаления стоп-слов, токенизации, нормализации регистра, а также синтаксического и морфологического анализа. Эти процедуры позволяют унифицировать текст, минимизировать шум и подготовить данные для дальнейшего анализа. Часто используются инструменты библиотеки NLTK или pymorphy2, обеспечивающие морфологическую нормализацию текста на русском языке [1].
После предобработки важной задачей становится извлечение признаков, описывающих текст. Для этого применяются TF-IDF, word2vec, fastText, трансформерные эмбеддинги (например, RuBERT). Последние особенно эффективны, так как позволяют учитывать контекст использования слов и выявлять глубинные семантические связи между фрагментами текста. Это существенно повышает качество анализа и интерпретации результатов.
Для выявления смысловых паттернов большое значение имеют методы тематического моделирования. В частности, алгоритм LDA (Latent Dirichlet Allocation) позволяет определить скрытые темы в текстах и выделить семантически близкие группы документов. Более современные подходы, такие как BERTopic, сочетают преимущества трансформеров и кластеризации, что даёт более гибкий и интерпретируемый результат. BERTopic использует эмбеддинги предложений (например, от моделей типа Sentence-BERT), после чего применяет алгоритмы уменьшения размерности (UMAP) и плотностную кластеризацию (HDBSCAN) [3].
Модель RuBERT строит контекстно-зависимые представления слов, что позволяет выявлять тонкие семантические различия и тематические паттерны даже в сложных текстах. Это делает её особенно полезной в задачах кластеризации смыслов, тематического моделирования и извлечения знаний [3].
Дополнительно важны методы статистического анализа, такие как анализ коллокаций с использованием Pointwise Mutual Information (PMI), позволяющий выявлять устойчивые словосочетания — биграммы и триграммы, характерные для определённой тематики [2]. Это помогает лучше интерпретировать тематику и структуру текста, а также способствует выявлению скрытых закономерностей. В контексте анализа текстов PMI позволяет определить, является ли биграмма или триграмма смысловой и устойчивой, а не просто случайной комбинацией слов. Формула для определения, является ли биграмма или триграмма смысловой:
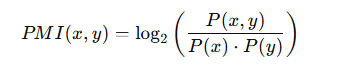
где:
P(x,y) — вероятность совместного появления слов x и y в биграмме;
𝑃 (𝑥) P(x), 𝑃 (𝑦) P(y) — вероятности появления слов x и y по отдельности.
Интерпретация значения PMI:
Высокое значение PMI (> 3–5) → слова часто встречаются вместе и образуют устойчивую фразу (например, «искусственный интеллект»).
PMI ≈ 0 → слова встречаются вместе не чаще, чем случайно.
Низкое/отрицательное значение PMI → слова не связаны или даже «избегают» совместного употребления.
Семантическое моделирование также играет ключевую роль в формировании смысловых паттернов. Использование моделей семейства BERT, в том числе русскоязычного RuBERT, позволяет получать контекстуальные векторные представления слов и предложений. Это, в свою очередь, делает возможным более глубокий анализ смысловых связей, чем классические статистические подходы.
Актуальность применения таких методов особенно высока в сфере интеллектуального анализа данных, автоматического мониторинга, анализа общественного мнения, выявления рисков и предиктивной аналитики. Например, в государственном управлении возможно выявление ключевых проблемных тем на основе анализа обращений граждан; в бизнесе — анализ отзывов клиентов для совершенствования продуктов и услуг; в науке — автоматическая категоризация и обзор научных публикаций.
Научная новизна подхода заключается в систематическом применении современных методов анализа больших текстовых данных для выявления смысловых паттернов, способных служить основой принятия решений. Использование моделей трансформерного типа в сочетании с тематическим и статистическим анализом позволяет перейти от поверхностного анализа текста к глубокому смысловому моделированию.
Таким образом, теоретическая база, рассматриваемая в настоящем исследовании, демонстрирует потенциал применения методов анализа текста в разнообразных практических задачах. Современные достижения в области NLP открывают возможности для интеллектуального извлечения знаний из неструктурированных данных, что является важным этапом в построении систем поддержки принятия решений.
Литература:
1. Томашевская, В. С. Использование машинного обучения для распознавания текстовых шаблонов литературных источников / В. С. Томашевская, Ю. В. Старичкова, Д. А. Яковлев. — Текст: непосредственный // Известия высших учебных заведений. Поволжский регион. Технические науки. — 2022. — № 3. — С. 16–18.
2. Краснов, Ф. В. Оценка прикладного качества тематических моделей для задач кластеризации / Ф. В. Краснов, Е. Н. Баскакова, И. С. Смазневич. — Текст: непосредственный // Вестник Томского государственного университета. Управление, вычислительная техника и информатика. — 2021. — № 56. — С. 100–102.
3. Разработка и исследование моделей многоклассовых классификаторов для рекомендательной системы подготовки заявок на портале единой информационной системы в сфере закупок / Я. А. Селиверстов, А. А. Комиссаров, А. А. Лесоводская [и др.]. — Текст: непосредственный // Информатика, телекоммуникации и управление. — 2022. — № 2. — С. 44–48.

