Статья посвящена задаче текстонезависимой идентификации диктора по голосу. Рассматривается наиболее подходящий алгоритм, основанный на GMM-UBM системе, применимый к малым объемам голосовых данных, что наиболее часто встречается на практике. Проводится тестирование и оценка системы.
Ключевые слова: GMM, UBM, MFCC, идентификация по голосу.
Задача идентификации по голосу изучается уже больше 40 лет. Поиск наиболее эффективного решения этой задачи имеет большую важность для таких сфер деятельности, как, например, банковское дело и криминалистика. В первом случае технология распознавания по голосу позволит отойти от таких старых методов, как кодовые слова, и не заставит прерывать беседу между клиентом и работником банка. Во втором случае эта технология может применяться для идентификации подозреваемых по записи.
Обычно нет возможности получить достаточно много голосовых данных для одного человека, чтобы использовать системы с высокой точностью, такие как нейронные сети, поскольку приходилось бы растягивать разговор, что было бы неудобно, например, для клиента банка. Поэтому делается акцент на разработке системы, применимой к малому объему исходных данных.
Процесс идентификации можно разделить на три этапа:
- Предварительная обработка данных;
- Вычисление голосовых признаков;
- Применение алгоритма идентификации и верификации.
Каждый этап играет большую роль во всей системе идентификации.
При предварительной обработке данных с записи необходимо удалить те участки, на которых отсутствует голос диктора, что позволить сократить влияние шума на результат идентификации (рисунок 1).
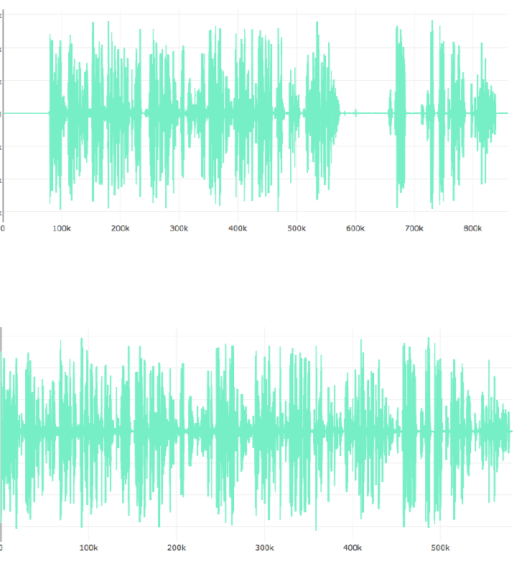
Рис. 1. Сигнал до и после удаления шумов и пауз
Наиболее эффективными являются методы, основанные на энергии или на статистических данных шума. Все эти методы основаны на том, что в начале записи, когда человек еще не успел ничего сказать, присутствует только шум, который можно проанализировать.
Весь сигнал делится на отдельные равные участки, называемые фреймами. Затем, в случае с энергией, высчитывается энергия Ei каждого фрейма и среднее значение энергии для всей записи E. Если Ei < k * E, где k < 1, то на этом фрейме тишина. Значение k подбирается экспериментально [1].
Следующий этап — это превратить обработанную запись голоса в вектора признаков, которые будут в дальнейшем использоваться для обучения или идентификации.
Наиболее популярным выбором при работе со звуком являются мел-частотные кепстральные коэффициенты MFCC (Mel-Frequency Cepstral Coefficients) [2]. Особенностью данного подхода является полученного вектора характеристик от длины исходного сигнала и учет в нем разброса индивидуальных особенностей, говорящего. Схема расчета коэффициентов MFCC представлен на рисунке 2.
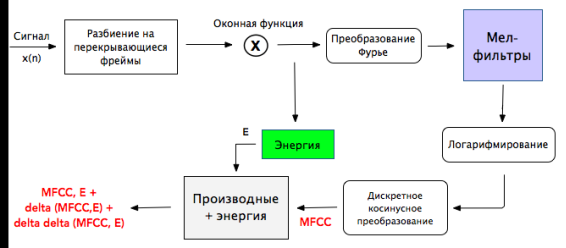
Рис. 2. Вычисление коэффициентов MFCC
- разбиваем на пересекающиеся фреймы;
- получаем спектр сигнала, применив к нему преобразование Фурье;
- раскладываем спектр по мел-шкале с помощью треугольных фильтров;
- возводим полученные значения в квадрат и логарифмируем — таким образом спектр будет больше соответствовать тому, как человек воспринимает звук;
- применяем к полученному набору коэффициентов дискретное косинусное преобразование, в результате чего получаем вектор MFСС.
- к вектору MFCC дополнительно высчитываем энергию, дельта и двойные дельта значения для каждого фрейма
После получения векторов признаков необходимо применить алгоритм идентификации и верификации. При идентификации мы находим диктора, наиболее близкого к тестовой записи, а при верификации принимаем решение, принадлежит ли тестовая запись группе дикторов, участвующих в обучении. Практическая интерпретация верификации заключается, например, в определении, зарегистрирован пользователь или нет.
Для реализации алгоритма идентификации используется GMM-UBM система. GMM (Gaussian Mixture Model) — это модель гауссовых смесей, которая будет представлять собой модель диктора. При таком подходе исходные данные представляются в виде кластеров, описываемых гауссианами (рисунок 3).
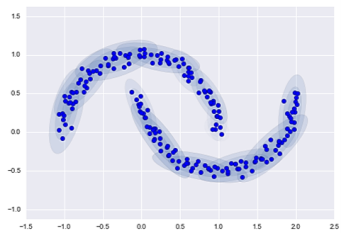
Рис. 3. Модель гауссовых смесей
Модель гауссовых смесей определяется векторами математического ожидания ![]() , ковариационной матрицей ∑, векторами весов
, ковариационной матрицей ∑, векторами весов ![]() и количеством компонент смеси M. Для определения первых трех значений используется обучение с помощью алгоритмов k-средних и EM (Expectation Maximization) методом максимального правдоподобия [3].
и количеством компонент смеси M. Для определения первых трех значений используется обучение с помощью алгоритмов k-средних и EM (Expectation Maximization) методом максимального правдоподобия [3].
UBM (Universal Background Model) — это GMM, обученная на относительно большом количестве голосовых данных. При GMM-UBM подходе модели отдельных дикторов обучаются с помощью MAP адаптации (Maximum A-Posteriori Adaptation) [4]. При таком подходе смещаются математические ожидания в сторону новых данных. Преимуществом UBM является быстрая адаптация новых дикторов и требования небольшого количества данных для этого.
Для идентификации диктора сначала необходимо найти модель, наиболее близкую к тесовой записи.
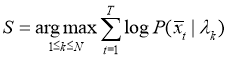
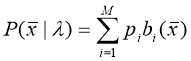
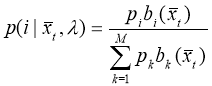
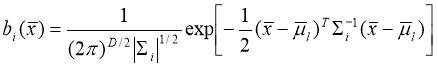
Здесь ![]() — соответственно значения весов, математических ожиданий и ковариационных матриц модели, а в качестве
— соответственно значения весов, математических ожиданий и ковариационных матриц модели, а в качестве ![]() обозначается модель,
обозначается модель, ![]() — вектор признаков. М — количество компонент гауссовой смеси, D — размерность вектора признаков.
— вектор признаков. М — количество компонент гауссовой смеси, D — размерность вектора признаков.
После нахождения наиболее близкой модели необходимо отнести запись к зарегистрированному или незарегистрированному пользователю. Для этого рассчитывается следующий показатель:
![]()
На основе сравнения этого значения с порогом и принимается решение о тестируемом дикторе.
Для тестирования построенной системы идентификации был собран набор из 100 дикторов. С помощью метода скользящего контроля были получены следующие метрики оценки качества системы.
Для этого определим следующую матрицу ошибок (таблица 1):
Таблица 1
Матрица ошибок
|
Зарегистрированные |
Незарегистрированные | |
|
Приняты системой |
TP (true positives) = 95 |
FN (false negatives) = 44 |
|
Не приняты системой |
FP (false positives) = 5 |
TN (true negative) = 356 |
Пусть P = TP + FN, N = TN + FP, P' = TP + FP, N' = FN + TN. Тогда, на основе этих значений можно получить значения следующих мер качества:
− Точность (accuracy) ![]()
− Полнота (recall) ![]()
− Точность (precision) 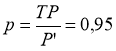
− F — мера ![]()
Построенная система позволяет достаточно точно идентифицировать зарегистрированного диктора, однако допускает ошибки при принятии решения о незарегистрированном. Для дальнейшего улучшения системы необходимо рассмотреть и другие методы предобработки, вычисления голосовых признаков и построения модели дикторов, применимых к малому объему данных.
Литература:
- Verteletskaya, E., and Sakhnov, K. Voice activity detection for speech enhancement applications // Acta Polytechnica. 2010. № 50, 4.
- S. Davis, P. Mermelstein Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences. // IEEE transactions on acoustics, speech, and signal processing. 1980. № 28, 4. С. 357–366.
- Jeff A. Bilmes A Gentle Tutorial of the EM Algorithm and its Application to Parameter Estimation for Gaussian Mixture and Hidden Markov Models // International Computer Science Institute Berkeley CA. 1998. С. 7–13.
- Reynolds, D. A., Quatieri, T. F., Dunn, R. B. Speaker verification using adapted gaussian mixture models // Digital signal processing. 2000. № 10, 1. С. 19–41.

